In this article we are going to see how we can read excel sheets in Python language. To do this we will be using openpyxl library which is used to read and write to an excel file.
Python Program to Read an Excel File Using Openpyxl Module
In Python we have openpyxl library which is used to create, modify, read and write different types of excel files like xlsx/xlsm/xltx/xltm etc. When user operates with thousands of records in a excel file and want to pick out few useful information or want to change few records then he/she can do it very easily by using openpyxl library.
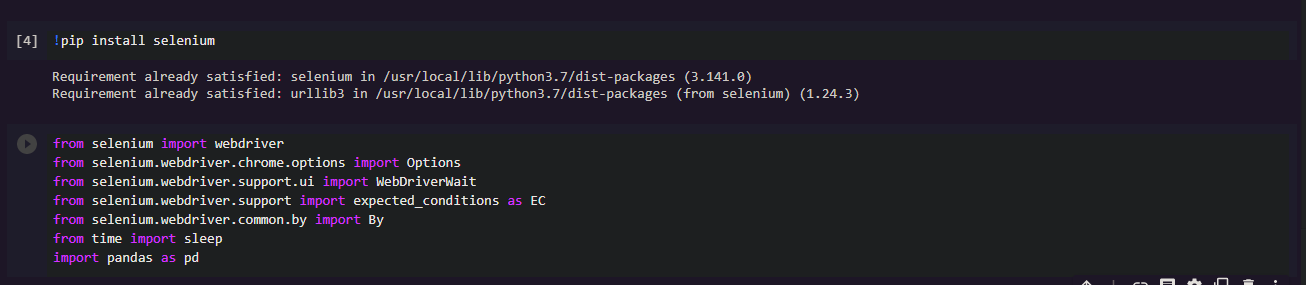
To use openpyxl library we first have to install it using pip.
Command : pip install openpyxl
After installation we can use the library to create and modify excel files.
Let’s see different programs to understand it more clearly.
-
- Python Program to Print a Particular Cell Value of Excel File Using Openpyxl Module
- Python Program to Print Total Number of Rows in Excel File Using Openpyxl Module
- Python Program to Print Total Number of Columns in Excel File Using Openpyxl Module
- Python Program to Print All Column Names of Excel File Using Openpyxl Module
- Python Program to Print First Column Value of Excel File Using Openpyxl Module
- Python Program to Print a Particular Row Value of Excel File Using Openpyxl Module
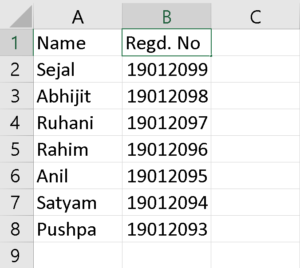
Input File:
Program-1: Python Program to Print a Particular Cell Value of Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule - Store the path to the excel workbook in a variable
- Load the workbook using the
load_workbook( )function passing the path as a parameter - From the workbook object we created, we extract the active sheet from the active attribute
- Then we create cell objects from the active sheet object
- Print the value from the cell using the value attribute of the cell object
Program:
# Import the openpyxl library import openpyxl as opxl # Path to the excel file path = "E:\\Article\\Python\\file1.xlsx" # Created a workbook object that loads the workbook present # at the path provided wb = opxl.load_workbook(path) # Getting the active workbook sheet from the active attribute activeSheet = wb.active # Created a cell object from the active sheet using the cell name cell1 = activeSheet['A2'] # Printing the cell value print(cell1.value)
Output:
Sejal
Program-2: Python Program to Print Total Number of Rows in Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule - Store the path to the excel workbook in a variable
- Load the workbook using the
load_workbook( )function passing the path as a parameter - From the workbook object we created, we extract the active sheet from the active attribute
- Then we print the number of rows using the
max_rowattribute of the sheet object
Program:
# Import the openpyxl library
import openpyxl as opxl
# Path to the excel file
path = "E:\\Article\\Python\\file1.xlsx"
# Created a workbook object that loads the workbook present
# at the path provided
wb = opxl.load_workbook(path)
# Getting the active workbook sheet from the active attribute
activeSheet = wb.active
# Printing the number of rows in the sheet
print("Number of rows : ", activeSheet.max_row)
Output:
Number of rows : 7
Program-3: Python Program to Print Total Number of Columns in Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule - Store the path to the excel workbook in a variable
- Load the workbook using the
load_workbook( )function passing the path as a parameter - From the workbook object we created, we extract the active sheet from the active attribute
- Then we print the number of columns using the
max_columnattribute of the sheet object
Program:
# Import the openpyxl library
import openpyxl as opxl
# Path to the excel file
path = "E:\\Article\\Python\\file1.xlsx"
# Created a workbook object that loads the workbook present
# at the path provided
wb = opxl.load_workbook(path)
# Getting the active workbook sheet from the active attribute
activeSheet = wb.active
# Printing the number of columns in the sheet
print("Number of columns : ", activeSheet.max_column)
Output:
Number of columns : 2
Program-4: Python Program to Print All Column Names of Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule - Store the path to the excel workbook in a variable
- Load the workbook using the
load_workbook( )function passing the path as a parameter - From the workbook object we created, we extract the active sheet from the active attribute
- Then we find and store the number of columns in a variable cols
- We run a for loop
from 1 to cols+1that creates cell objects and prints their value
Program:
# Import the openpyxl library
from ast import For
import openpyxl as opxl
# Path to the excel file
path = "E:\\Article\\Python\\file1.xlsx"
# Created a workbook object that loads the workbook present
# at the path provided
wb = opxl.load_workbook(path)
# Getting the active workbook sheet from the active attribute
activeSheet = wb.active
# Number of columns
cols = activeSheet.max_column
# Printing the column names using a for loop
for i in range(1, cols + 1):
currCell = activeSheet.cell(row=1, column=i)
print(currCell.value)
Output:
Name Regd. No
Program-5: Python Program to Print First Column Value of Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule. - Store the path to the excel workbook in a variable.
- Load the workbook using the
load_workbook( )function passing the path as a parameter. - From the workbook object we created, we extract the active sheet from the active attribute.
- Then we find and store the number of rows in a variable
rows. - We run a for loop
from 1 to rows+1that creates cell objects and prints their value.
Program:
# Import the openpyxl library
from ast import For
import openpyxl as opxl
# Path to the excel file
path = "E:\\Article\\Python\\file1.xlsx"
# Created a workbook object that loads the workbook present
# at the path provided
wb = opxl.load_workbook(path)
# Getting the active workbook sheet from the active attribute
activeSheet = wb.active
# Number of rows
rows = activeSheet.max_row
# Printing the first column values using for loop
for i in range(1, rows + 1):
currCell = activeSheet.cell(row=i, column=1)
print(currCell.value)
Output:
Name Sejal Abhijit Ruhani Rahim Anil Satyam Pushpa
Program-6: Python Program to Print a Particular Row Value of Excel File Using Openpyxl Module
Approach:
- First of all we have to import the
openpyxlmodule. - Store the path to the excel workbook in a variable.
- Load the workbook using the
load_workbook( )function passing the path as a parameter. - From the workbook object we created, we extract the active sheet from the active attribute.
- We use a variable
rowNumto store the row number we want to read values from and acolsvariable that stores the total number of columns. - We run a for loop
from 1 to cols+1that creates cell objects of the specified rows and prints their value.
Program:
# Import the openpyxl library
from ast import For
import openpyxl as opxl
# Path to the excel file
path = "E:\\Article\\Python\\file1.xlsx"
# Created a workbook object that loads the workbook present
# at the path provided
wb = opxl.load_workbook(path)
# Getting the active workbook sheet from the active attribute
activeSheet = wb.active
# Number of columns
cols = activeSheet.max_column
# The row number we want to print from
rowNum = 2
# Printing the row
for i in range(1, cols + 1):
currCell = activeSheet.cell(row=rowNum, column=i)
print(currCell.value)
Output:
Sejal 19012099