
Web Scraping:
Web scraping is used to extract the data from the website and it can save time as well as effort. In this article, we will be extracting hundreds of file from the New York MTA. Some people find web scraping tough, but it is not the case as this article will break the steps into easier ones to get you comfortable with web scraping.
New York MTA Data:
We will download the data from the below website:
http://web.mta.info/developers/turnstile.html
Turnstile data is compiled every week from May 2010 till now, so there are many files that exist on this site. For instance, below is an example of what data looks like.
You can right-click on the link and can save it to your desktop. That is web scraping!
Important Notes about Web scraping:
- Read through the website’s Terms and Conditions to understand how you can legally use the data. Most sites prohibit you from using the data for commercial purposes.
- Make sure you are not downloading data at too rapid a rate because this may break the website. You may potentially be blocked from the site as well.
Inspecting the website:
The first thing that we should find out is the information contained in the HTML tag from where we want to scrape it. As we know, there is a lot of code on the entire page and it contains multiple HTML tags, so we have to find out the one which we want to scrape and write it down in our code so that all the data related to it will be visible.
When you are on the website, right-click and then when you will scroll down you will get an option of “inspect”. Click on it and see the hidden code behind the page.
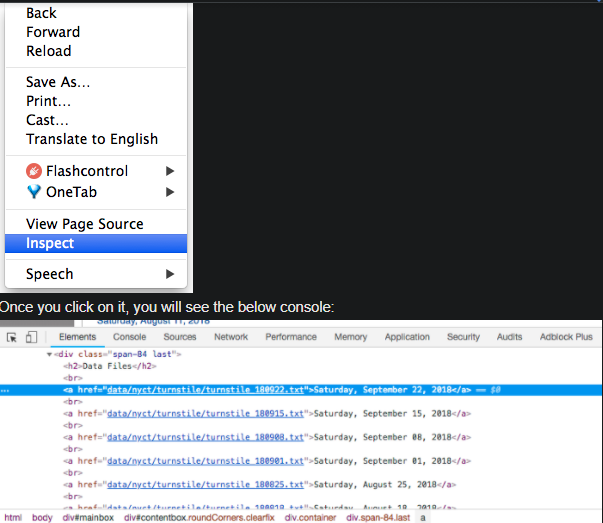
You can see the arrow symbol at the top of the console.
- Web crawling and scraping in Python
- What can you do with python: Usage guide | 9 Cool Things to do with Python Programming
- Literals in Python
If you will click on the arrow and then click any text or item on the website then the highlighted tag will appear related to the website on which you clicked.
I clicked on Saturday, September 2018 file and the console came in the blue highlighted part.
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
You will see that all the .txt files come in <a> tags. <a> tags are used for hyperlinks.
Now that we got the location, we will process the coding!
Python Code:
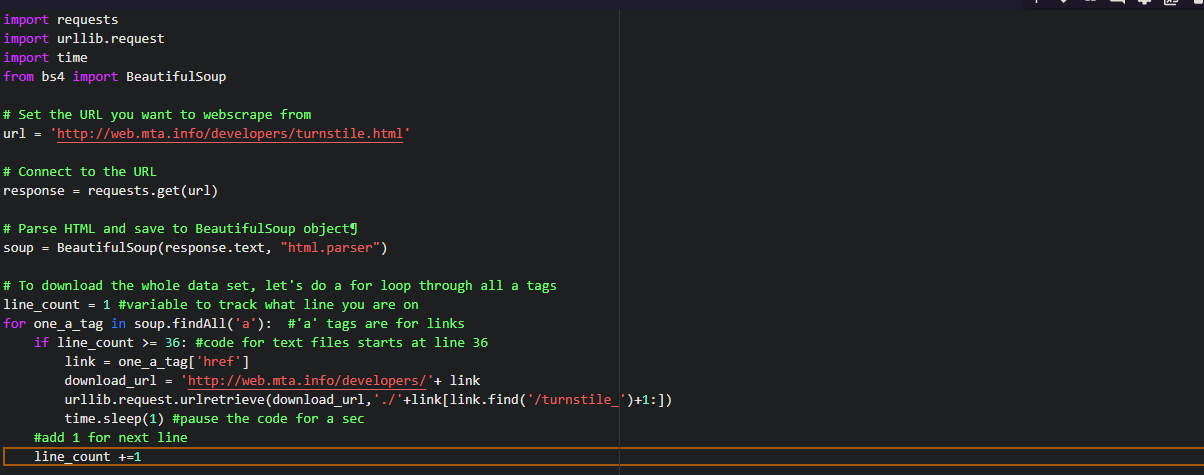
The first and foremost step is importing the libraries:
import requests import urllib.request import time from bs4 import BeautifulSoup
Now we have to set the url and access the website:
url = '
http://web.mta.info/developers/turnstile.html’
response = requests.get(url)
Now, we can use the features of beautiful soup for scraping.
soup = BeautifulSoup(response.text, “html.parser”)
We will use the method findAll to get all the <a> tags.
soup.findAll('a')
This function will give us all the <a> tags.
Now, we will extract the actual link that we want.
one_a_tag = soup.findAll(‘a’)[38] link = one_a_tag[‘href’]
This code will save the first .txt file to our variable link.
download_url = 'http://web.mta.info/developers/'+ link urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
For pausing our code we will use the sleep function.
time.sleep(1)
To download the entire data we have to apply them for a loop. I am attaching the entire code so that you won’t face any problem.
I hope you understood the concept of web scraping.
Enjoy reading and have fun while scraping!
An Intro to Web Scraping with lxml and Python:
Sometimes we want that data from the API which cannot be accessed using it. Then, in the absence of API, the only choice left is to make a web scraper. The task of the scraper is to scrape all the information which we want in easily and in very little time.
The example of a typical API response in JSON. This is the response from Reddit.
There are various kinds of python libraries that help in web scraping namely scrapy, lxml, and beautiful soup.
Many articles explain how to use beautiful soup and scrapy but I will be focusing on lxml. I will teach you how to use XPaths and how to use them to extract data from HTML documents.
Getting the data:
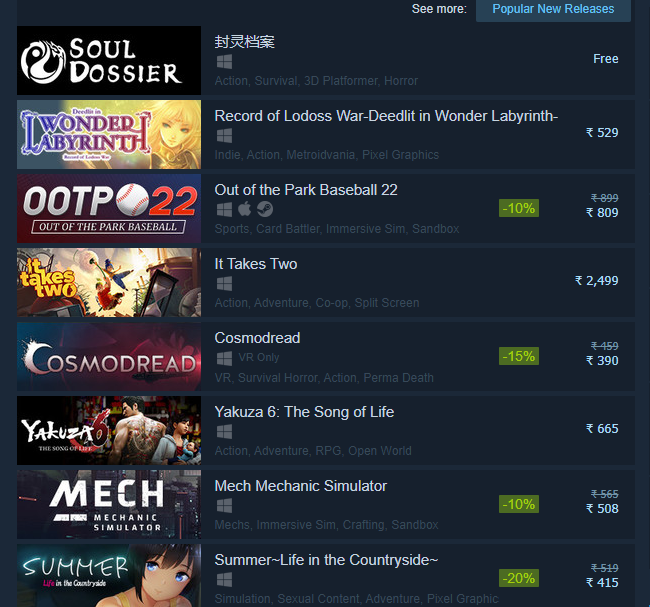
If you are into gaming, then you must be familiar with this website steam.
We will be extracting the data from the “popular new release” information.
Now, right-click on the website and you will see the inspect option. Click on it and select the HTML tag.
We want an anchor tag because every list is encapsulated in the <a> tag.
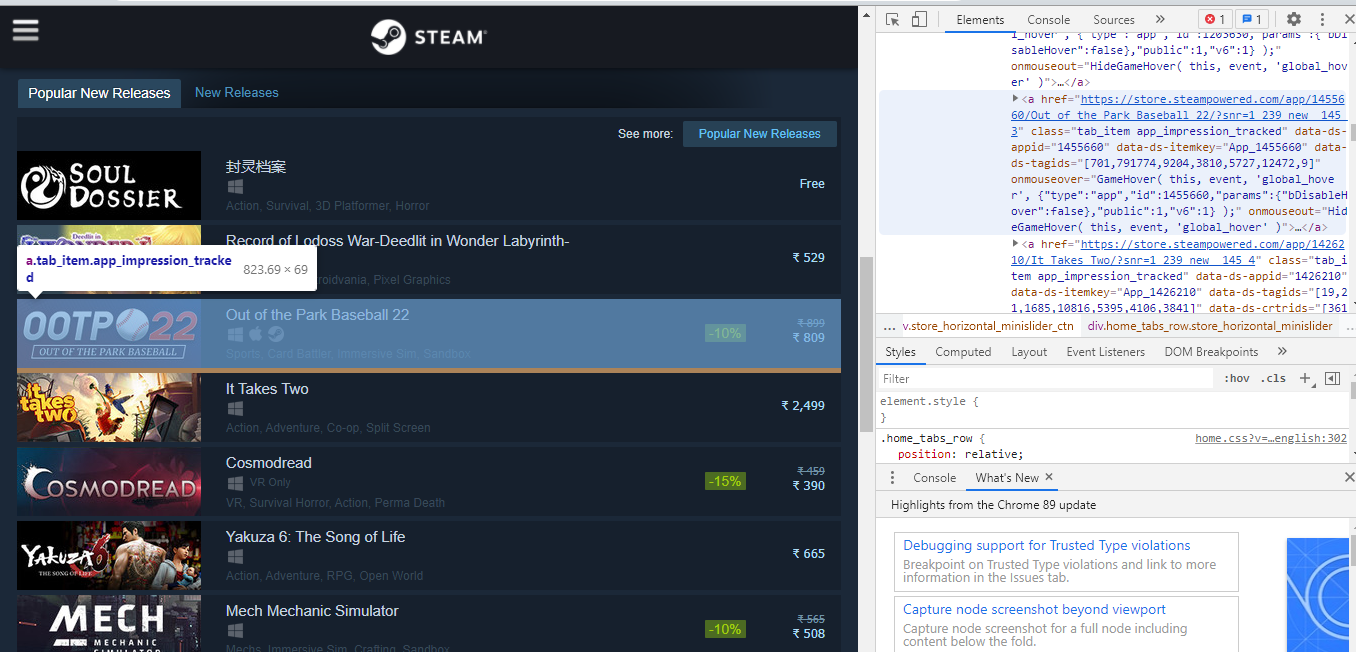
The anchor tag lies in the div tag with an id of tag_newreleasecontent. We are mentioning the id because there are two tabs on this page and we only want the information of popular release data.
Now, create your python file and start coding. You can name the file according to your preference. Start importing the below libraries:
import requests import lxml.html
If you don’t have requests to install then type the below code on your terminal:
$ pip install requests
Requests module helps us open the webpage in python.
Extracting and processing the information:
Now, let’s open the web page using the requests and pass that response to lxml.html.fromstring.
html = requests.get('https://store.steampowered.com/explore/new/') doc = lxml.html.fromstring(html.content)
This provides us with a structured way to extract information from an HTML document. Now we will be writing an XPath for extracting the div which contains the” popular release’ tab.
new_releases = doc.xpath('//div[@id="tab_newreleases_content"]')[0]
We are taking only one element ([0]) and that would be our required div. Let us break down the path and understand it.
- // these tell lxml that we want to search for all tags in the HTML document which match our requirements.
- Div tells lxml that we want to find div tags.
- @id=”tab_newreleases_content tells the div tag that we are only interested in the id which contains tab_newrelease_content.
Awesome! Now we understand what it means so let’s go back to inspect and check under which tag the title lies.
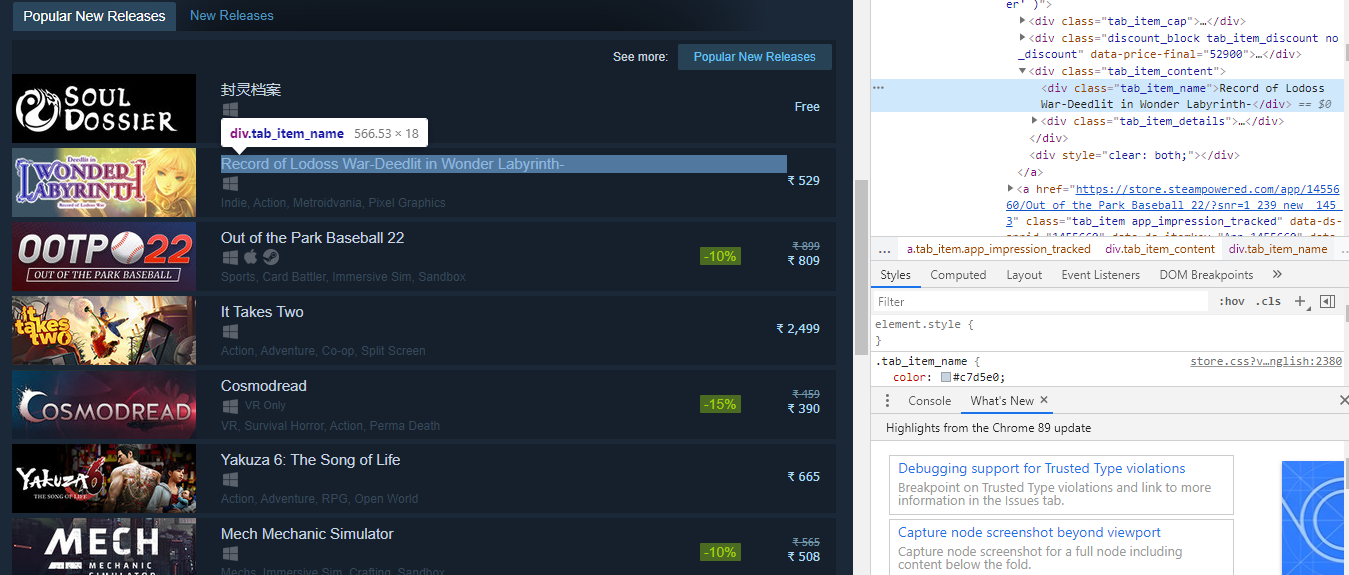
The title name lies in the div tag inside the class tag_item_name. Now we will run the XPath queries to get the title name.
titles = new_releases.xpath('.//div[@class="tab_item_name"]/text()')
We can see that the names of the popular releases came. Now, we will extract the price by writing the following code:
prices = new_releases.xpath('.//div[@class="discount_final_price"]/text()')

Now, we can see that the prices are also scraped. We will extract the tags by writing the following command:
tags = new_releases.xpath('.//div[@class="tab_item_top_tags"]') total_tags = [] for tag in tags: total_tags.append(tag.text_content())
We are extracting the div containing the tags for the game. Then we loop over the list of extracted tags using the tag.text_content method.

Now, the only thing remaining is to extract the platforms associated with each title. Here is the the HTML markup:
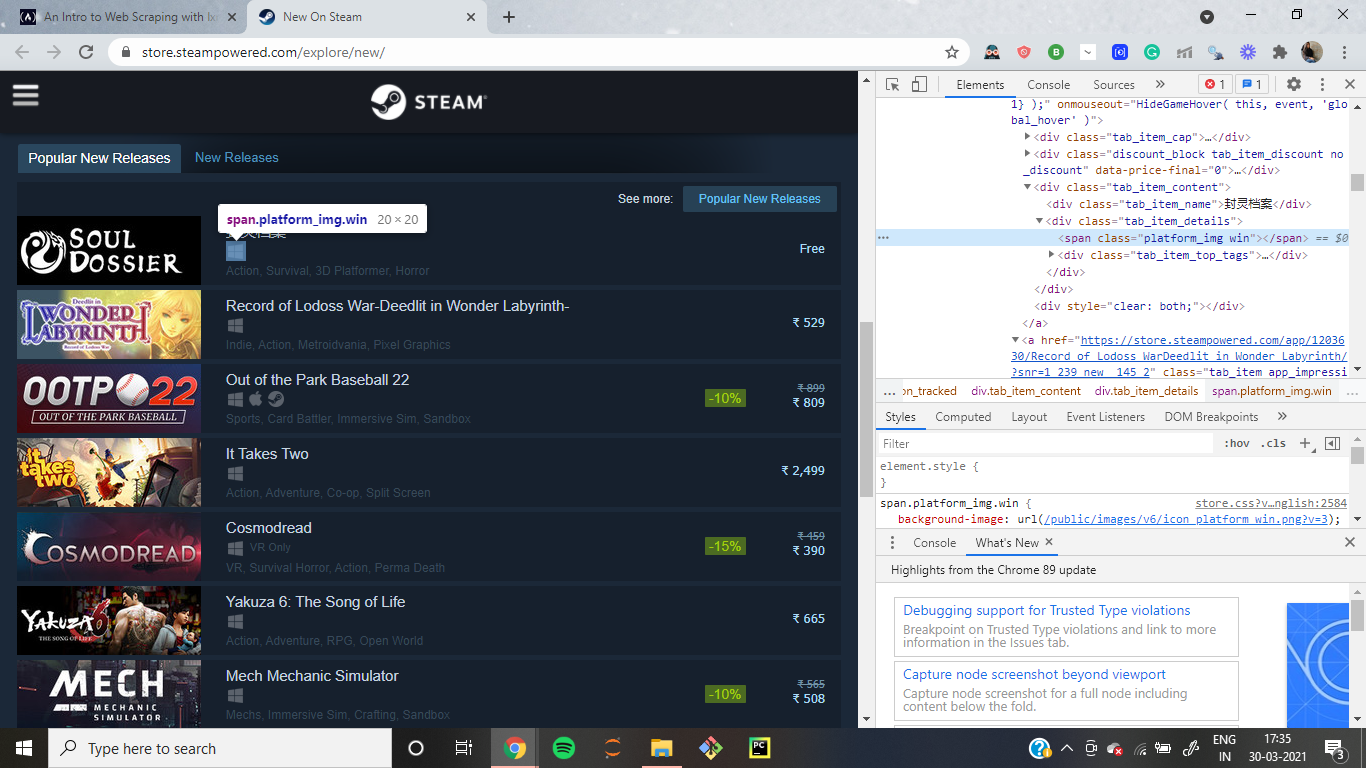
The major difference here is that platforms are not contained as texts within a specific tag. They are listed as class name so some titles only have one platform associated with them:
<span class="platform_img win"></span>
While others have 5 platforms like this:
<span class="platform_img win"></span><span class="platform_img mac"></span><span class="platform_img linux"></span><span class="platform_img hmd_separator"></span> <span title="HTC Vive" class="platform_img htcvive"></span> <span title="Oculus Rift" class="platform_img oculusrift"></span>
The span tag contains platform types as the class name. The only thing common between them is they all contain platform_img class.
First of all, we have to extract the div tags containing the tab_item_details class. Then we will extract the span containing the platform_img class. Lastly, we will extract the second class name from those spans. Refer to the below code:
platforms_div = new_releases.xpath('.//div[@class="tab_item_details"]') total_platforms = [] for game in platforms_div: temp = game.xpath('.//span[contains(@class, "platform_img")]') platforms = [t.get('class').split(' ')[-1] for t in temp] if 'hmd_separator' in platforms: platforms.remove('hmd_separator') total_platforms.append(platforms)
Now we just need this to return a JSON response so that we can easily turn this into Flask based API.
output = []for info in zip(titles,prices, tags, total_platforms): resp = {} resp['title'] = info[0] resp['price'] = info[1] resp['tags'] = info[2] resp['platforms'] = info[3] output.append(resp)
We are using the zip function to loop over all of the lists in parallel. Then we create a dictionary for each game to assign the game name, price, and platforms as keys in the dictionary.
Wrapping up:
I hope this article is understandable and you find the coding easy.
Enjoy reading!