

Selenium is a powerful tool for controlling web browsers through programs and performing browser automation. Selenium is also used in python for scraping the data. It is also useful for interacting with the page before collecting the data, this is the case that we will discuss in this article.
In this article, we will be scraping the investing.com to extract the historical data of dollar exchange rates against one or more currencies.
There are other tools in python by which we can extract the financial information. However, here we want to explore how selenium helps with data extraction.
The Website we are going to Scrape:
Understanding of the website is the initial step before moving on to further things.
Website consists of historical data for the exchange rate of dollars against euros.
In this page, we will find a table in which we can set the date range which we want.
That is the thing which we will be using.
We only want the currencies exchange rate against the dollar. If that’s not the case then replace the “usd” in the URL.
- Python Selenium Tutorial | Selenium Python Training for Beginners
- How to install Selenium in Python | Installing Selenium WebDriver Using Python and Chrome
- Building an RSS feed Scraper with Python
The Scraper’s Code:
The initial step is starting with the imports from the selenium, the Sleep function to pause the code for some time and the pandas to manipulate the data whenever necessary.
Now, we will write the scraping function. The function will consists of:
- A list of currency codes.
- A start date.
- An End date.
- A boolean function to export the data into .csv file. We will be using False as a default.
We want to make a scraper that scrapes the data about the multiple currencies. We also have to initialise the empty list to store the scraped data.

As we can see that the function has the list of currencies and our plan is to iterate over this list and get the data.
For each currency we will create a URL, instantiate the driver object, and we will get the page by using it.
Then the window function will be maximized but it will only be visible when we will keep the option.headless as False.
Otherwise, all the work will be done by the selenium without even showing you.

Now, we want to get the data for any time period.
Selenium provides some awesome functionalities for getting connected to the website.
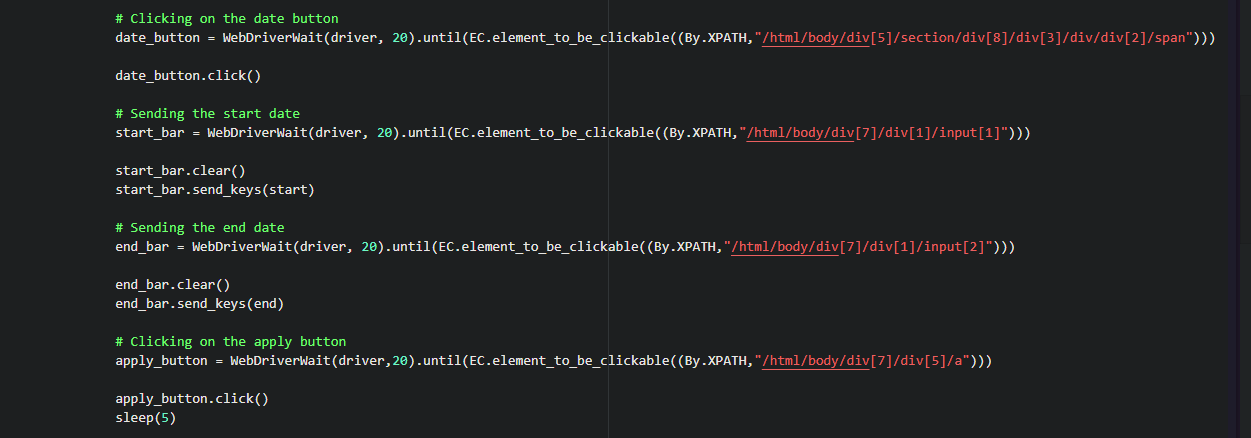
We will click on the date and fill the start date and end dates with the dates we want and then we will hit apply.
We will use WebDriverWait, ExpectedConditions, and By to make sure that the driver will wait for the elements we want to interact with.
The waiting time is 20 seconds, but it is to you whichever the way you want to set it.
We have to select the date button and it’s XPath.
The same process will be followed by the start_bar, end_bar, and apply_button.
The start_date field will take in the date from which we want the data.
End_bar will select the date till which we want the data.
When we will be done with this, then the apply_button will come into work.
Now, we will use the pandas.read_html file to get all the content of the page. The source code of the page will be revealed and then finally we will quit the driver.

How to handle Exceptions In Selenium:
The collecting data process is done. But selenium is sometimes a little unstable and fail to perform the function we are performing here.
To prevent this we have to put the code in the try and except block so that every time it faces any problem the except block will be executed.
So, the code will be like:
for currency in currencies:
while True:
try:
# Opening the connection and grabbing the page
my_url = f'https://br.investing.com/currencies/usd-{currency.lower()}-historical-data'
option = Options()
option.headless = False
driver = webdriver.Chrome(options=option)
driver.get(my_url)
driver.maximize_window()
# Clicking on the date button
date_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH,
"/html/body/div[5]/section/div[8]/div[3]/div/div[2]/span")))
date_button.click()
# Sending the start date
start_bar = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH,
"/html/body/div[7]/div[1]/input[1]")))
start_bar.clear()
start_bar.send_keys(start)
# Sending the end date
end_bar = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH,
"/html/body/div[7]/div[1]/input[2]")))
end_bar.clear()
end_bar.send_keys(end)
# Clicking on the apply button
apply_button = WebDriverWait(driver,20).until(
EC.element_to_be_clickable((By.XPATH,
"/html/body/div[7]/div[5]/a")))
apply_button.click()
sleep(5)
# Getting the tables on the page and quiting
dataframes = pd.read_html(driver.page_source)
driver.quit()
print(f'{currency} scraped.')
break
except:
driver.quit()
print(f'Failed to scrape {currency}. Trying again in 30 seconds.')
sleep(30)
Continue
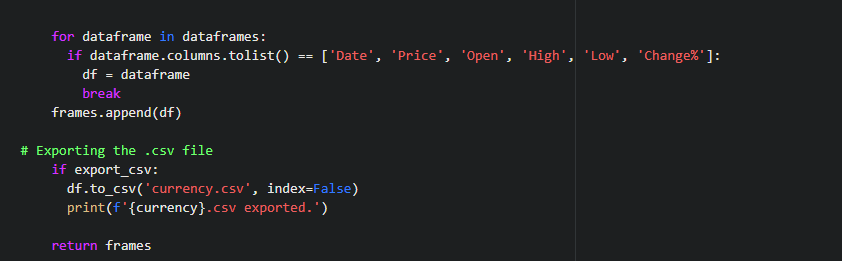
For each DataFrame in this dataframes list, we will check if the name matches, Now we will append this dataframe to the list we assigned in the beginning.
Then we will need to export a csv file. This will be the last step and then we will be over with the extraction.
Wrapping up:
This is all about extracting the data from the website.So far this code gets the historical data of the exchange rate of a list of currencies against the dollar and returns a list of DataFrames and several .csv files.
https://www.investing.com/currencies/usd-eur-historical-data