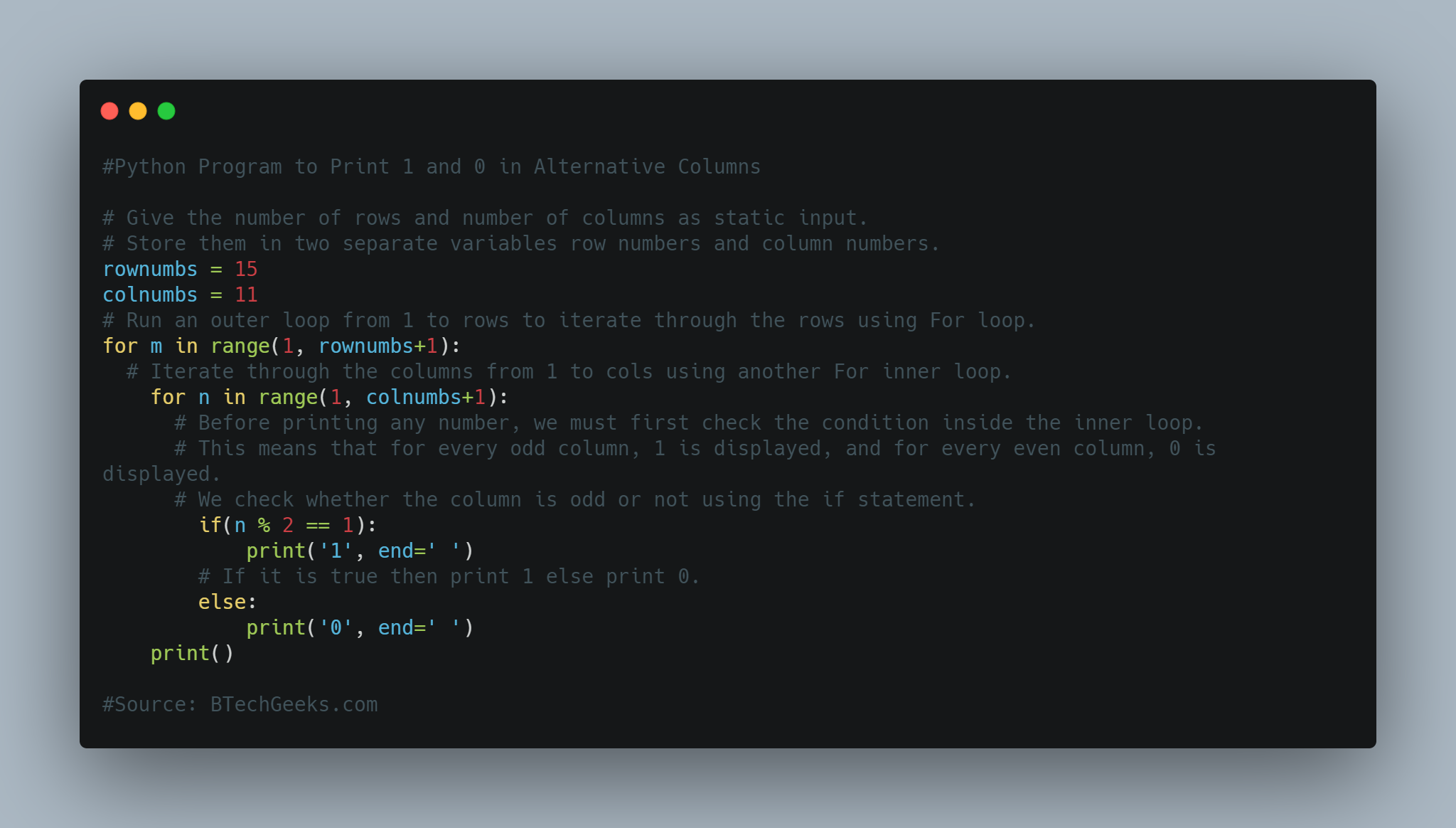
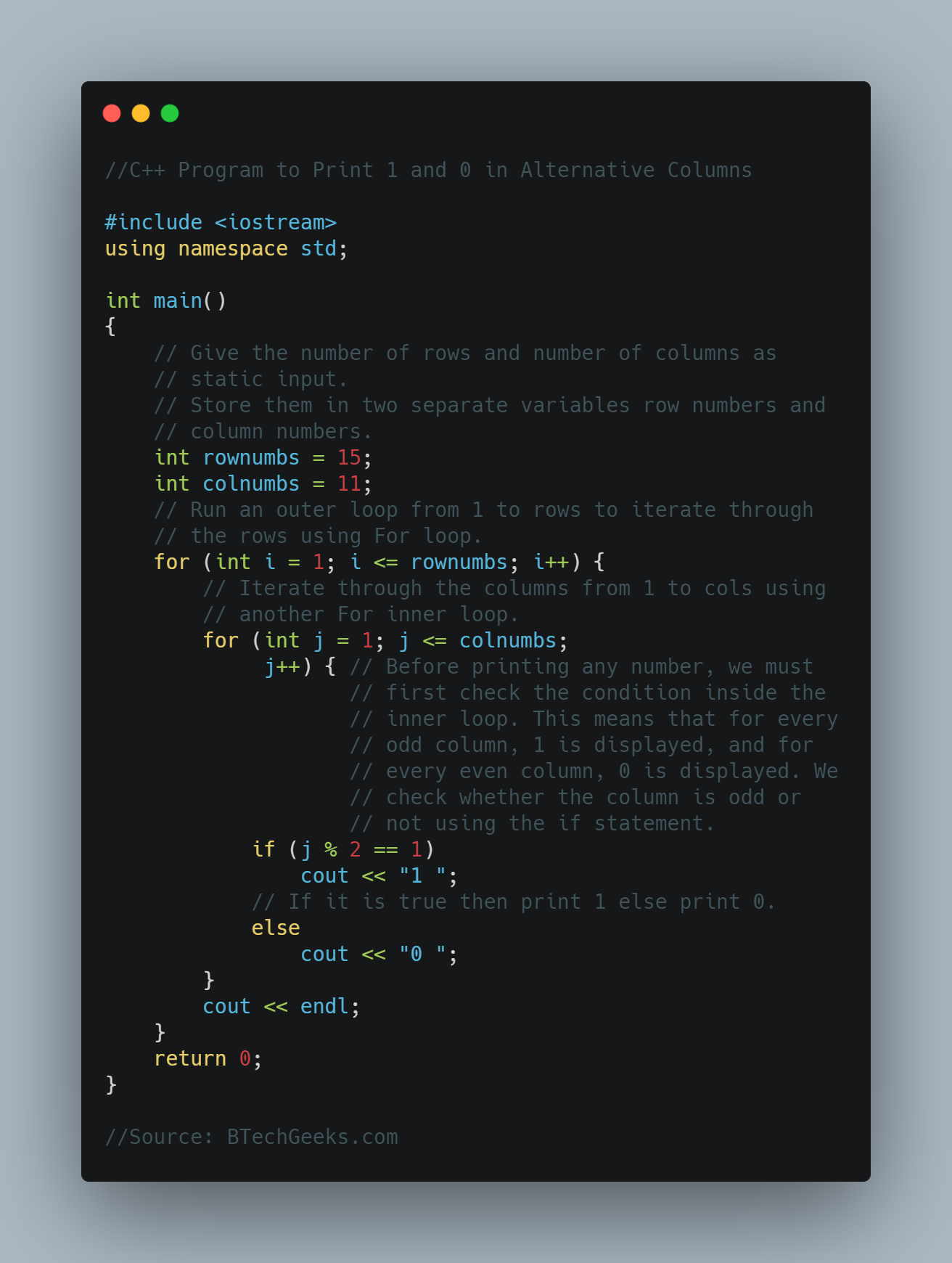
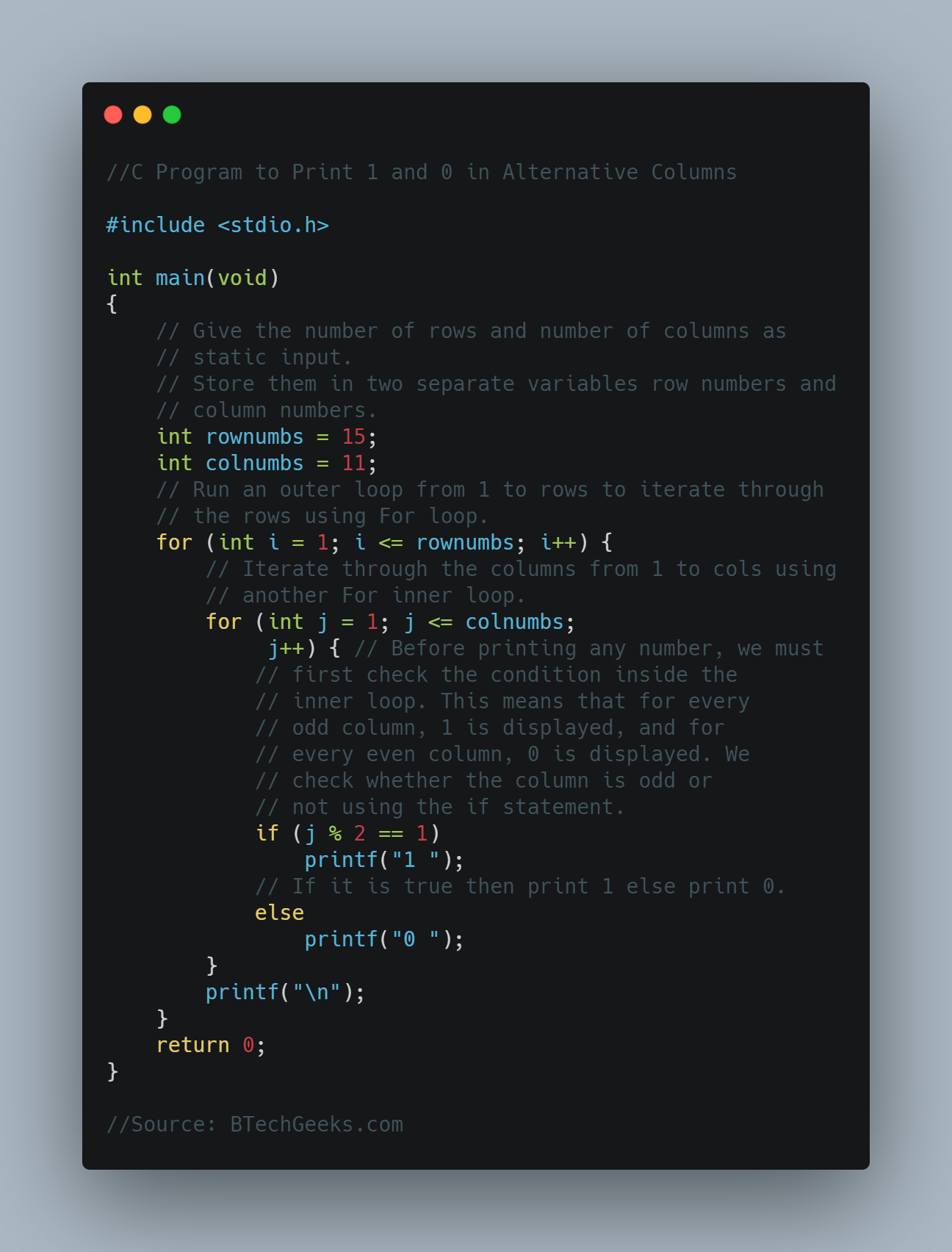
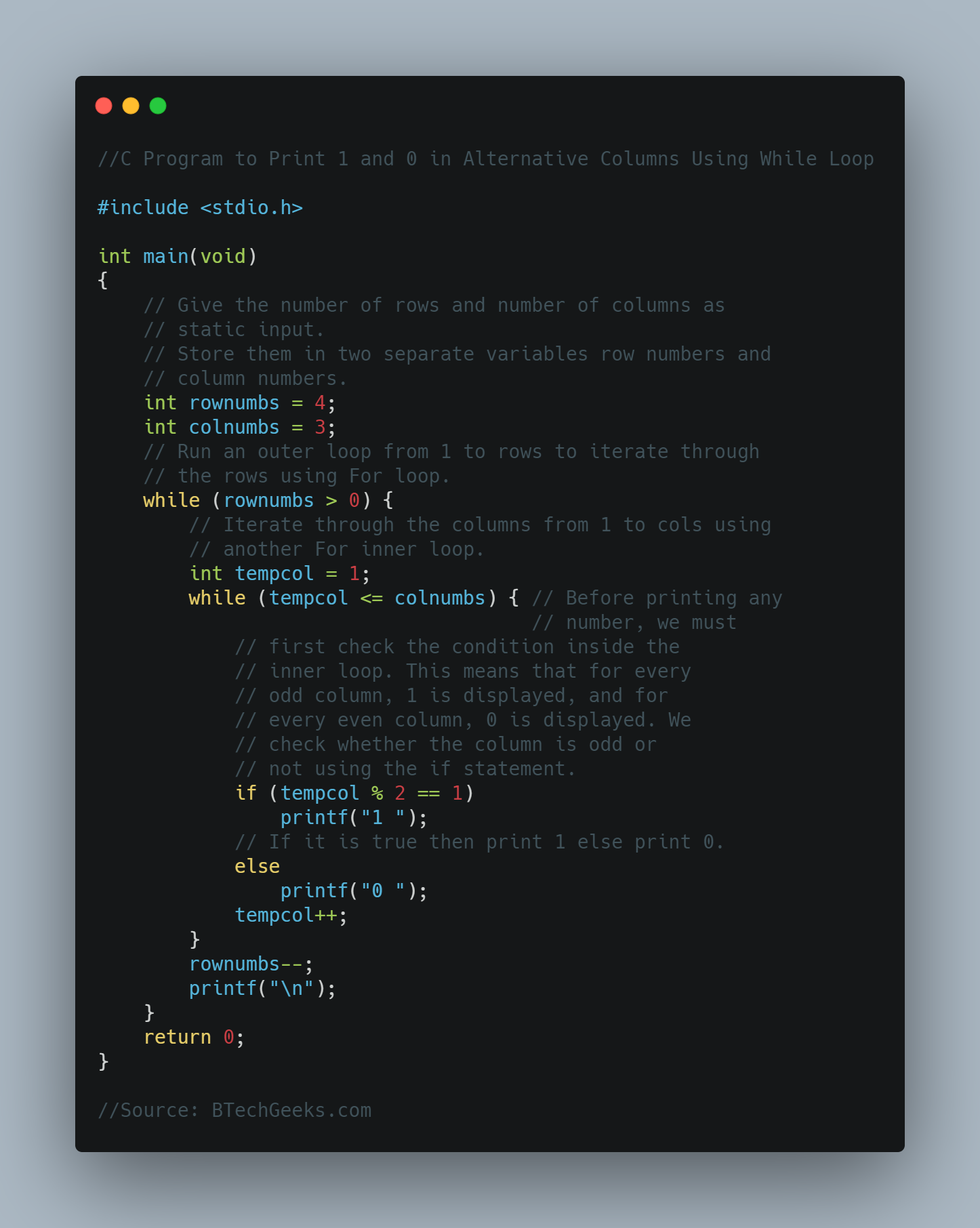
In the previous article, we have discussed Python Program for Pizza Cut Problem (Or Circle Division by Lines)
Given the coordinates of the center point as (0,0), the radius of the circle, and the equation of a line and the task is to check whether the given line touches or intersects the circle.
The line equation is in the form ax+by+c.
Hence a, b, c values are given for a line equation.
The three possibilities :
- The Line intersect the circle
- The Line touches the circle
- The Line outside the circle
The following formula can be used to calculate the distance of a line from a point:
(ax+by+c)/sqrt(a*a+b*b)
If d > r, the line lies outside the circle.
If d = r, the line touches the circle.
If d < r, the line intersects the circle.
where d = the distance of a line from a center.
r is the radius of the circle.
- Java Program to Check if a Line Touches or Intersects a Circle
- Python Program for Area of a Circumscribed Circle of a Square
- Python Program to Calculate Volume of Ellipsoid
Examples:
Example1:
Input:
Given radius = 6 Given a = 2 Given b = 1 Given c = 1
Output:
The Given line intersects the circle
Example2:
Input:
Given radius = 5 Given a = 1 Given b = 1 Given c = -15
Output:
The Given line is outside the circle
Program to Check If a Line Touches or Intersects a Circle in Python
Below are the ways to check whether the given line touches or intersects the circle in Python:
Method #1: Using Mathematical Formula (Static Input)
Approach:
- Import math module using the import keyword.
- Give the radius as static input and store it in a variable.
- Take the x-coordinate of the center and initialize its value to 0.
- Take the y-coordinate of the center and initialize its value to 0.
- Give the number as static input and store it in a variable.
- Give the other number as static input and store it in another variable.
- Give the third number as static input and store it in another variable.
- Calculate the distance of the given line from the given center point using the above given mathematical formula, abs(), math.sqrt() functions.
- Store it in another variable.
- Check if the given radius value is equal to the above-obtained distance using the if conditional statement.
- If it is true, then print “The Given line touches the circle”.
- Check if the given radius value is greater than the above-obtained distance using the elif conditional statement.
- If it is true, then print “The Given line intersects the circle”.
- Else, print “The Given line is outside the circle”.
- The Exit of the Program.
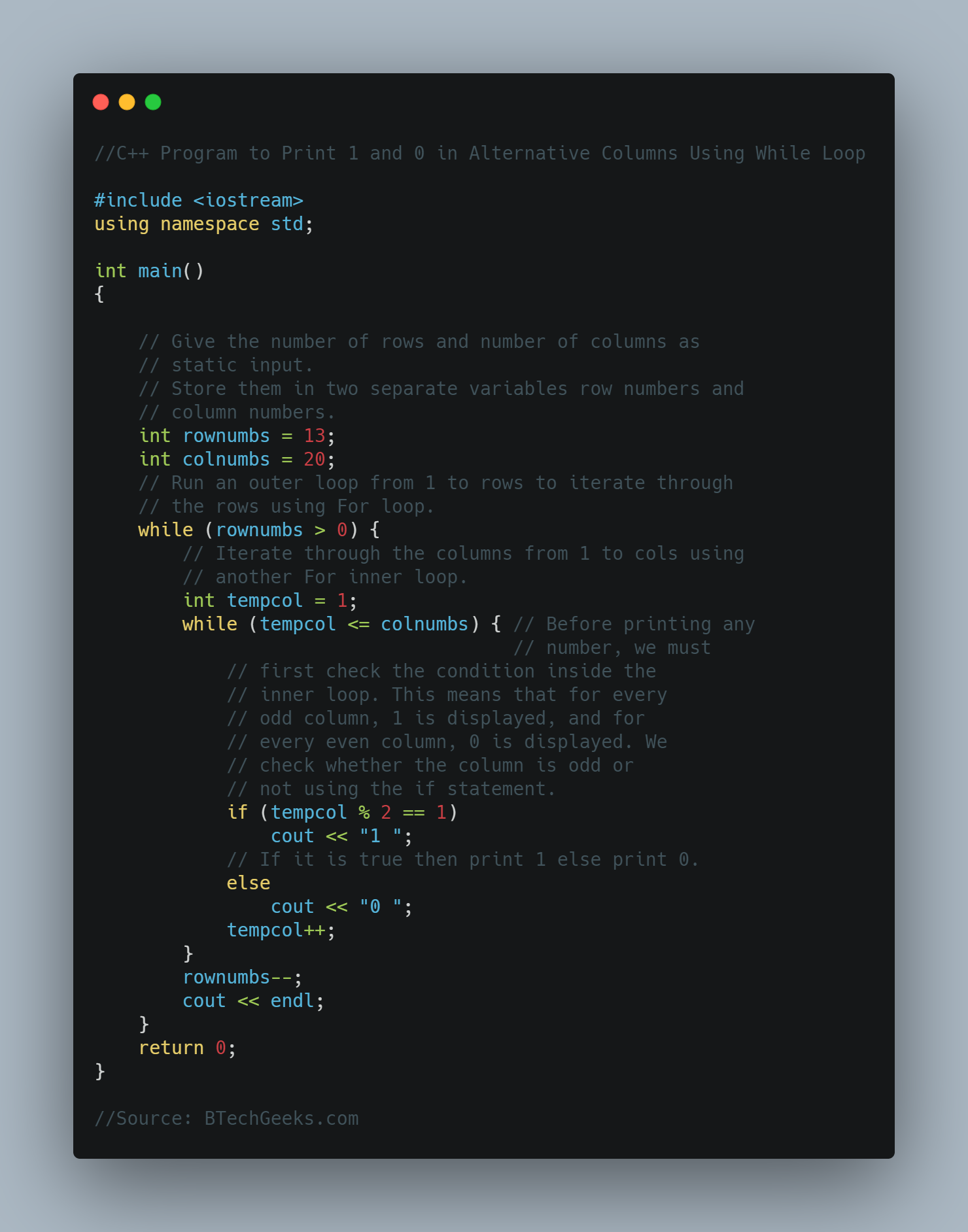
Below is the implementation:
# Import math module using the import keyword.
import math
# Give the radius as static input and store it in a variable.
gvn_radiuss = 6
# Take the x-coordinate of center and initialize its value to 0.
m = 0
# Take the y-coordinate of center and initialize its value to 0.
n = 0
# Give the number as static input and store it in a variable.
p = 2
# Give the other number as static input and store it in another variable.
q = 1
# Give the third number as static input and store it in another variable.
r = 1
# Calculate the distance of the given line from the given center point using the
# above given mathematical formula, abs(), math.sqrt() functions
# store it in another variable.
distancee_val = ((abs(p * m + q * n + r)) /
math.sqrt(p * p + q * q))
# Check if the given radius value is equal to the above obtained distance using the
# if conditional statement.
if (gvn_radiuss == distancee_val):
# If it is true, then print "The Given line touches the circle".
print("The Given line touches the circle")
# Check if the given radius value is greater than the above obtained distance using
# the elif conditional statement.
elif (gvn_radiuss > distancee_val):
# If it is true, then print "The Given line intersects the circle".
print("The Given line intersects the circle")
else:
# Else, print "The Given line is outside the circle".
print("The Given line is outside the circle")
Output:
The Given line intersects the circle
Method #2: Using Mathematical Formula (User Input)
Approach:
- Import math module using the import keyword.
- Give the radius as user input using the int(input()) function and store it in a variable.
- Take the x-coordinate of the center and initialize its value to 0.
- Take the y-coordinate of the center and initialize its value to 0.
- Give the number as user input using the int(input()) function and store it in a variable.
- Give the other number as user input using the int(input()) function and store it in another variable.
- Give the third number as user input using the int(input()) function and store it in another variable.
- Calculate the distance of the given line from the given center point using the above given mathematical formula, abs(), math.sqrt() functions.
- Store it in another variable.
- Check if the given radius value is equal to the above-obtained distance using the if conditional statement.
- If it is true, then print “The Given line touches the circle”.
- Check if the given radius value is greater than the above-obtained distance using the elif conditional statement.
- If it is true, then print “The Given line intersects the circle”.
- Else, print “The Given line is outside the circle”.
- The Exit of the Program.
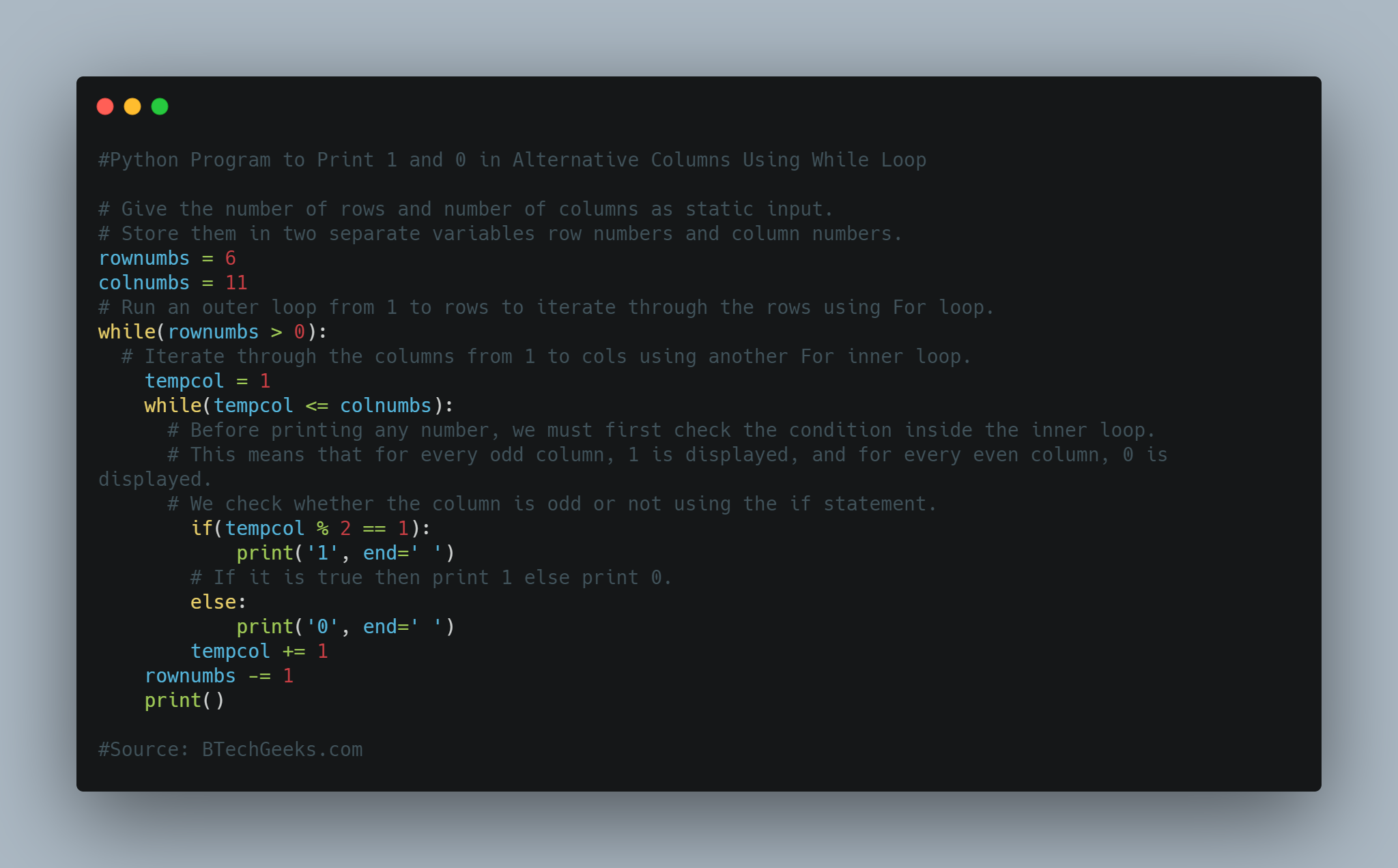
Below is the implementation:
# Import math module using the import keyword.
import math
# Give the radius as user input using the int(input()) function and
# store it in a variable.
gvn_radiuss = int(input("Enter some random number = "))
# Take the x-coordinate of center and initialize its value to 0.
m = 0
# Take the y-coordinate of center and initialize its value to 0.
n = 0
# Give the number as user input using the int(input()) function and store it in a variable.
p = int(input("Enter some random number = "))
# Give the other number as user input using the int(input()) function and store it in another variable.
q = int(input("Enter some random number = "))
# Give the third number as user input using the int(input()) function and store it in another variable.
r = int(input("Enter some random number = "))
# Calculate the distance of the given line from the given center point using the
# above given mathematical formula, abs(), math.sqrt() functions
# store it in another variable.
distancee_val = ((abs(p * m + q * n + r)) /
math.sqrt(p * p + q * q))
# Check if the given radius value is equal to the above obtained distance using the
# if conditional statement.
if (gvn_radiuss == distancee_val):
# If it is true, then print "The Given line touches the circle".
print("The Given line touches the circle")
# Check if the given radius value is greater than the above obtained distance using
# the elif conditional statement.
elif (gvn_radiuss > distancee_val):
# If it is true, then print "The Given line intersects the circle".
print("The Given line intersects the circle")
else:
# Else, print "The Given line is outside the circle".
print("The Given line is outside the circle")
Output:
Enter some random number = 5 Enter some random number = 1 Enter some random number = 1 Enter some random number = -15 The Given line is outside the circle
Enhance your coding skills with our list of Python Basic Programs provided and become a pro in the general-purpose programming language Python in no time.