Python Data Persistence – Python – PyMongo
is NOSQL?
In today’s era of real-time web applications, NoSQL databases are becoming increasingly popular. The term NoSQL originally referred to “non SQL” or “non-relational”, but its supporters prefer to call it “Not only SQL” to indicate that SQL-like query language may be supported alongside.
NoSQL is touted as open-source, distributed, and horizontally scalable schema-free database architecture. NoSQL databases are more scalable and provide superior performance as compared to RDBMS. This primarily because it requires that schemas (table structure, relationships, etc.) be defined before you can add data. Some of the popular NoSQL databases extensively in use today include MongoDB, CouchDB, Cassandra, HBase, etc.
Several NoSQL products are available in the market. They are classified into four categories based on the data model used by them.
Key-Value store: Uses a hash table (also called a dictionary). Each item in the database is stored as a unique attribute name (or ‘key’), associated with its value. The key-value model is the simplest type of NoSQL database. Examples of key-value databases are Amazon SimpleDB, Oracle BDB, Riak, and Berkeley DB.
Column Oriented: This type of databases store and process very large amount of data distributed over multiple machines. Keys point to multiple columns. The columns are arranged by column family. Examples of column-oriented databases are Cassandra and HBase.
Document oriented: Database of this category is an advanced key-value store database. The semi-structured documents are stored in formats like JSON. Documents can contain many different key-value pairs, or key- array pairs, or even nested documents.
Graph Based: Databases of this type are used to store information about networks of data, such as social connections. A flexible graph model can scale across multiple machines. Graph stores include Neo4J and Giraph.
In this chapter, we shall get acquainted with a hugely popular document-oriented database, MongoDB, and how it can be interfaced with Python through the PyMongo module.
- Python Data Persistence – PyMongo – Relationships
- Python Data Persistence – A Quick Guide
- Python Data Persistence – Python – Cassandra
MongoDB
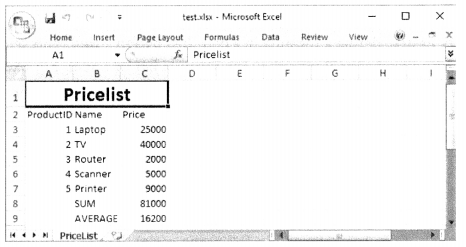
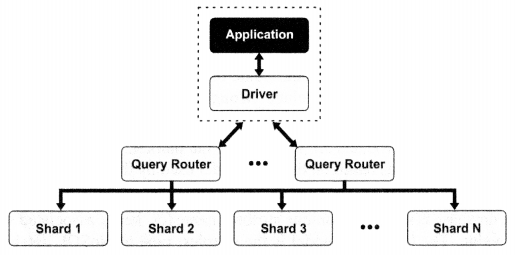
NoSQL databases typically have a huge amount of data. Hence, more often than not, the power of a single CPU is not enough when it comes to fetching data corresponding to a query. MongoDB uses a sharding technique that splits data sets across multiple instances. A large collection of data is split across multiple physical servers called ‘shards’, even though they behave as one collection. Query request from the application is routed to the appropriate shard and the result is served. Thus, MongoDB achieves horizontal scalability, (figure 11.1)
The Document is the heart of a MongoDB database. It is a collection of key-value pairs – similar to Python’s dictionary object. We can also think of it being similar to a single row in a table of SQL-based relational databases.
Collection in MongoDB is analogous to a table in the relational database. However, it doesn’t have a predefined schema. The Collection has a dynamic schema in the sense each document may of a variable number of k-v pairs not necessarily with the same keys in each document.
Each document is characterized by a special key called “_id” having a unique value, again similar to a primary key in the entity table of a relational database.
MongoDB server has a command-line interface from inside which different database operations can be performed.
MongoDB – Create Database
To display the current database in use, there’s a DB command. The default database in-use tests.
> db Test
With the ‘use’ command any other database is set as current. If the named database doesn’t exist, a new one is created.
> use mydb switched to db mydb
However, until you store data(such as collection or document) in it, is the database is not created. The following command inserts a document in the ‘products’ collection under the current database.
MongoDB – Insert Document
Appropriately, insertone ( ) method is available to a collection object in a database. A document is provided to it as a parameter.
> db.products.insertone({"ProductID":1,
"Name":"Laptop", "Price":25000})
WriteResult({ "nlnserted" : 1 })
Result of above (for that matter any insert/update/delete operation) command returns WriteResult object. The insert () method inserts multiple documents if the argument is an array of documents. In that case, the result is BulkWriteResult object.
> var pricelist=[{'productID' :1, 'Name': 'Laptop' , 'price':25000},
. . . { 'productID' : 2, 'Name":'TV' , 'price':2000},
. . . { 'productID' : 3, 'Name":'Router' , 'price':2000},
. . . { 'productID' : 4, 'Name":'Scanner' , 'price':5000},
. . . { 'productID' : 5, 'Name":'Printer' , 'price':9000},
> db.products.insert(pricelist);
BulkWriteResult ({
"writeErrors" : [ ] ,
"writeConcernErrors" : [ ] ,
"nInserted" : 5 ,
"nUpserted" : 0 ,
"nMatched" : 0 ,
"nModified" : 0 ,
"nRemoved" : 0 ,
"upserted" : [ ]
})
The insert () function inserts a single document or array whereas a single document is inserted with inserOne ( ) method and array whereas the insert_many () method is used with an array.
MongoDB – Delete Document
The remove () method deletes one or more documents from the collection based on the provided criteria. The following statement will result in the removal of a document pertaining to price>40000 (in our data it happens to be with name=’TV’).
> db.products.remove({"price":{$gt:40000}})
WriteResult({ "nRemoved" : 1 })
Run the find ( ) method in the shell to verify the removal.
Now that, we have attained some level of familiarity with MongoDB with the help of shell commands. Let us concentrate on our main objective – use MongoDB in Python.
PyMongo – Update Document
PyMongo offers two collection methods for the modification of data in one or more documents. They are update_one () and update_many () . Both require filter criteria and a new value of one or more keys. The update_one () updates only the first document that satisfies filter criteria. On the other hand, update__many () performs updates on all documents that satisfy the filter criteria.
collection.update_one (filter, newval)
Following Python script accepts the name of the product from the user and displays the current price. It is updated to the new price input by the user.
Example
> var pricelist=[{'productID' :1, 'Name': 'Laptop' , 'price':25000},
. . . { 'productID' : 2, 'Name":'TV' , 'price':2000},
. . . { 'productID' : 3, 'Name":'Router' , 'price':2000},
. . . { 'productID' : 4, 'Name":'Scanner' , 'price':5000},
. . . { 'productID' : 5, 'Name":'Printer' , 'price':9000},
> db.products.insert(pricelist);
BulkWriteResult ({
"writeErrors" : [ ] ,
"writeConcernErrors" : [ ] ,
"nInserted" : 5 ,
"nUpserted" : 0 ,
"nMatched" : 0 ,
"nModified" : 0 ,
"nRemoved" : 0 ,
"upserted" : [ ]
})
Python Data Persistence – pyMongo – Querying Collection
PyMongo module defines find( ) method to be used with a collection object. It returns a cursor object which provides a list of all documents in the collection.
>>> products=db['products']
>>> docs=products .find ()
>>> list(docs)
[{'_id' : Objectld('5c8dec275405cl2e3402423c'),
'ProductID': 1, 'Name': 'Laptop', 'price': 25000},
{'_id': ObjectId('5c8dec275405cl2e3402423d'),
'ProductID': 2, 'Name': 'TV', 'price': 50000},
{'_id': Objectld('5c8dec275405cl2e3402423e'),
'ProductID': 3, 'Name': 'Router', 'price': 2000},
{'_id': Objectld('5c8dec275405cl2e3402423f'),
'ProductID': 4, 'Name': 'Scanner', 'price': 5000},
{'_id': Objectld('5c8dec275405cl2e34024240'),
'ProductID': 5, 'Name': 'Printer', 'price': 9000}]
This cursor object is an iterator that serves one document for every call of the next () method. Each document is a dictionary object of k-v pairs. The following code displays the name and GSTIN of all customers.
Example
#mongofind. py
from pymongo import MongoClient
client=MongoClient( )
db=client.newdb
cust=db['customers']
docs=cust. find ( )
while True:
try:
doc=docs.next()
print (doc['Name'], doc['GSTIN'])
except Stoplteration:
break
client.close ( )
Run the above script from the command prompt.
E : \python3 7 >python mongofind. py Ravikumar 27AAJPL7103N1ZF Patel 24ASDFG1234N1ZN Nitin 27AABBC7895N1ZT Nair 32MMAF8963N1ZK Shah 24BADEF2002N1ZB Khurana 07KABCS1002N1ZV Irfan 05IIAAV5103N1ZA Kiran 12PPSDF22431ZC Divya 15ABCDE1101N1ZA John 29AAEEC4258E1ZK
You can, of course, employ a regular ‘for’ loop to traverse the cursor object to obtain one document at a time.
Example
for doc in docs:
print (doc['Name'] , doc[1GSTIN'])
The logical operators of MongoDB (described earlier in this chapter) are used to apply filter criteria for the find ( ) method. As an example, products with price>10000 are fetched with the following statement:
Example
>>> products=db['products']
>>> docs=products .find
({'price :{ 1$gt ' :10000} } )
>>> for
doc in docs: print (doc.get('Name'),
doc.get('price')) Laptop 25000 TV 50000