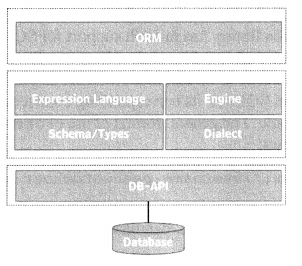
Python Data Persistence – pyodbc Module
ODBC is a language and operating system independent API for accessing relational databases. The product module enables access to any RDBMS for which the respective ODBC driver is available on the operating system. Most of the established relational database products (Oracle, MySQL, PostgreSQL, SQL Server, etc.) have ODBC drivers developed by the vendors themselves or third-party developers.
In this section, we access ‘mydb’ database deployed on the MySQL server. First of all, verify if your OS has a corresponding ODBC driver installed. If not, download MYSQL/ODBC connector compatible with your OS, MySQL version, and hardware architecture from MySQL’s official download page: https://dev.mysql.com/downloads/connector/odbc/ and perform the installation as per instructions.
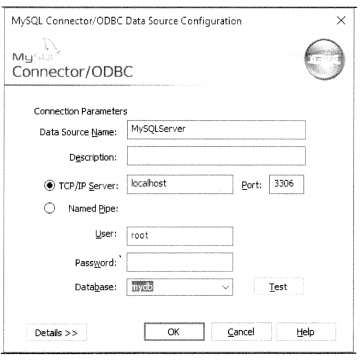
The following discussion pertains to MySQL ODBC on Windows OS. You need to open the ODBC Data Sources app in the Administrative Tools section of the control panel, add a newly installed MySQL driver, if it doesn’t have the same already, and configure it to identify by a DSN (Data Source Name) with the help of MySQL sever’s user ID and password, pointing towards ‘mydb’ database.(figure 8.1)
- Python Data Persistence – RDBMS Products
- Java Database Connectivity (JDBC) Interview Questions in Java
- Python Data Persistence – Python – Cassandra
This ‘MySQLDSN’ is now available for use in any application including our Python interpreter. You need to install pyodbc module for that purpose.
Start the Python interpreter and import this module. Its connect () function takes the DSN and other login credentials as arguments.
Example
>>> con=pyodbc.connect("DSN=MYSQLDSN;UID=root")
Once we obtain the connection object, the rest of the operations are exactly similar to that described with reference to the sqlite3 module. You can try creating Customers and Invoices tables in mydb database using their earlier structure and sample data.
In conclusion, we can say that the DB-API specification has made database handling very easy and more importantly uniform. However, data in SQL tables is stored basically in primary data types only which are mapped to corresponding built-in data types of Python. Python’s user-defined objects can’t be persistently stored and retrieved to/from SQL tables. The next chapter deals with the mapping of Python classes to SQL tables.