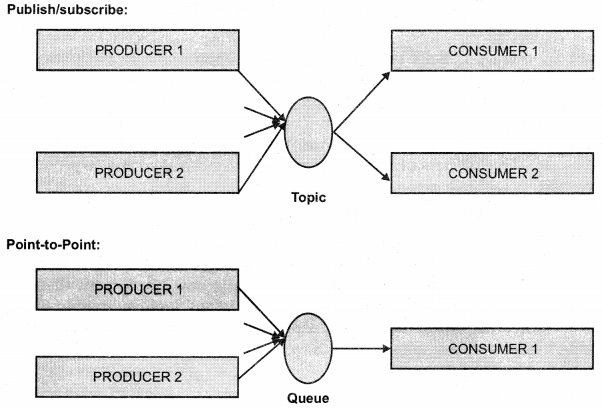
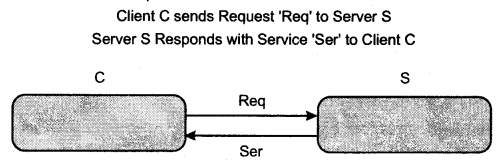
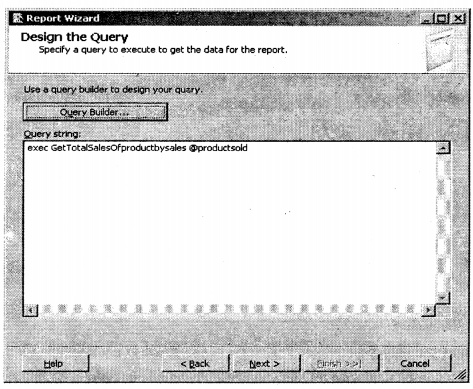
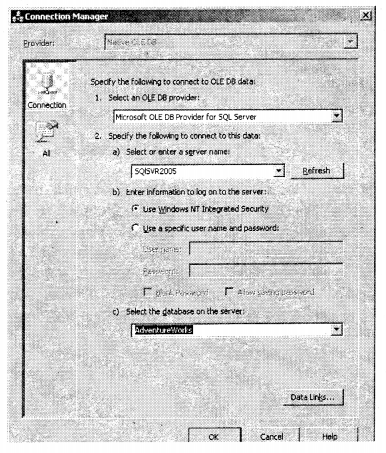
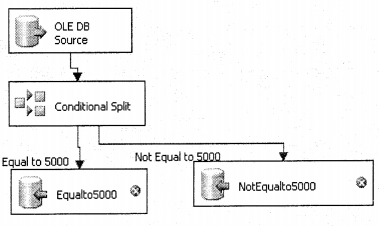
We have compiled most frequently asked SQL Server Interview Questions which will help you with different expertise levels.
SQL Server Interview Questions on Database Optimization
Question 1.
What are indexes?
Answer:
Index makes your search faster. So defining indexes to your database will make your search faster.
Question 2.
What are B-Trees?
Answer:
Most of the indexing fundamentals use “B-Tree” or “Balanced-Tree” principle. It’s not a principle that is something is created by SQL Server but is a mathematical derived fundamental.
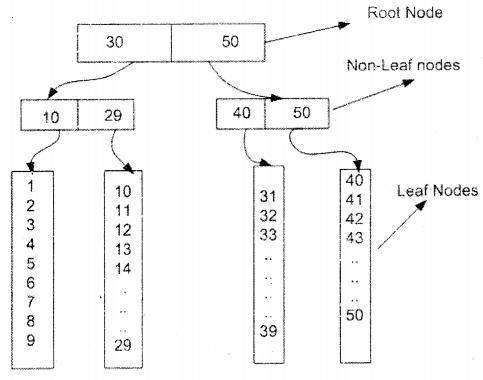
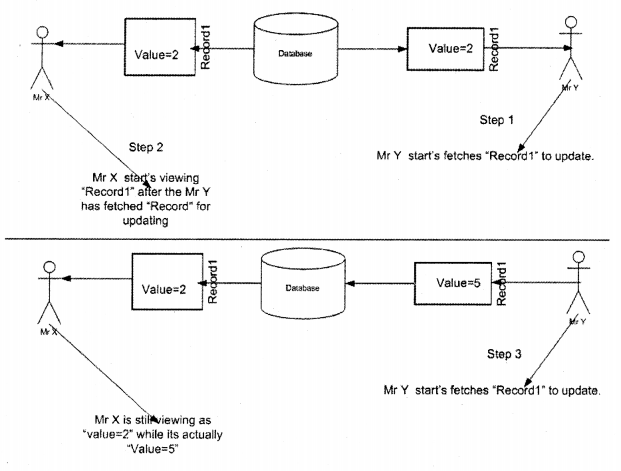
Above is a sample diagram which explains how B-Tree fundamental works. The above diagram is showing how index will work for number from 1-50. Let’s say you want to search 39. SQL Server will first start from the first node i.e. root node.
It will see that the number is greater than 30, so it moves to the 50 node.
- Further in Non-Leaf nodes it compares is it more than 40 or less than 40. As it’s less than 40 it loops through the leaf nodes which belong to 40 nodes.
You can see that this is all attained in only two steps.. .faster aaah. That is how exactly indexes work in SQL Server.
Question 3.
I have a table which has lot of inserts, is it a good database design to create indexes on that table?
Answer:
Twist: – Insert’s are slower on tables that have indexes, justify it?
Twist: – Why do page splitting happen?
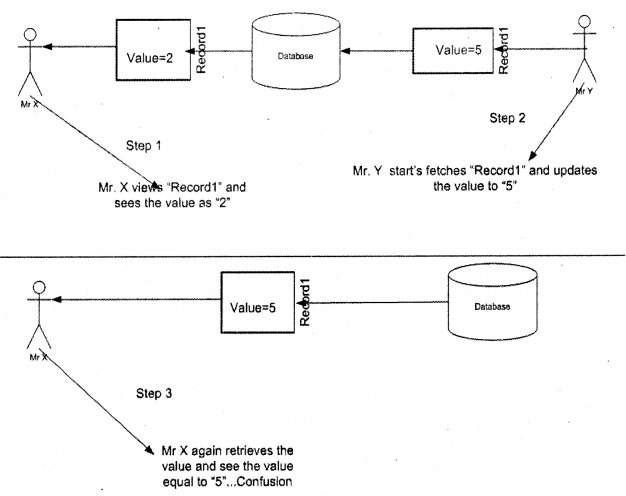
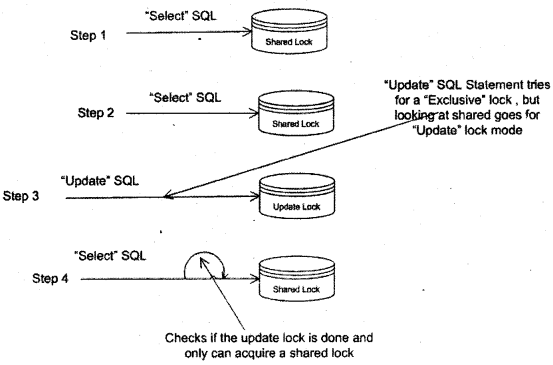
“B-Tree” stands for balanced tree. In order that “B-tree” fundamental work properly both of the sides should be balanced. All indexing fundamentals in SQL Server use “B-tree” fundamental. Now whenever there is new data inserted or deleted the tree tries to become unbalance. In order that we can understand the fundamental properly let’s try to refer the figure down.
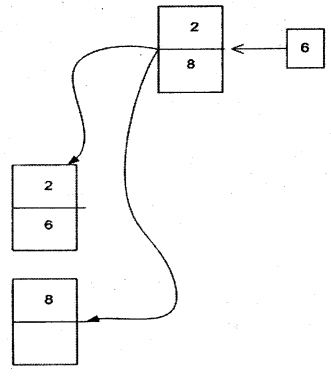
If you see the first level index there is “2” and “8”, now let say we want to insert “6”. In order to balance the “B-TREE” structure rows it will try to split in two pages, as shown. Even though the second page split has some empty area it will go ahead because the primary thing for him is balancing the “B-TREE” for fast retrieval.
Now if you see during the split it is doing some heavy-duty here:-
- Creates a new page to balance the tree.
- Shuffle and move the data to pages.
So if your table is having heavy inserts that means it’s transactional, then you can visualize the number of splits it will be doing. This will not only increase insert time but will also upset the end-user who is sitting on the screen.
So when you forecast that a table has a lot of inserts it’s not a good idea to create indexes.
Question 4.
What are “Table Scan’s” and “Index Scan’s”?
Answer:
These are ways by which SQL Server searches a record or data in a table. In “Table Scan” SQL Server loops through all the records to get to the destination. For instance, if you have 1, 2, 5, 23, 63, and 95. If you want to search for 23 it will go through 1, 2, and 5 to reach it. Worst if it wants to search 95 it will loop through all the records.
While for “Index Scan’s” it uses the. “B-TREE” fundamental to get to a record. For “B-TREE” refer to previous questions.
Note Which way to search is chosen by SQL Server engine. Example if itfinds that the table records are
very less it will go for table scan. If itfinds the table is huge it will gofor index scan.
Question 5.
What are the two types of indexes and explain them in detail?
Answer:
Twist: – What’s the difference between clustered and non-clustered indexes?
There are basically two types of indexes:-
- Clustered Indexes.
- Non-Clustered Indexes.
Ok, every7 thing is the same for both the indexes i.e. it uses “B-TREE” for searching data. But the main difference is the way it stores physical data. If you remember the previous figure (give figure number here) there were leaf level and non-leaf level. Leaf level holds the key which is used to identify the record. And non-leaf level actually points to the leaf level.
In a clustered index, the non-leaf level actually points to the actual data.
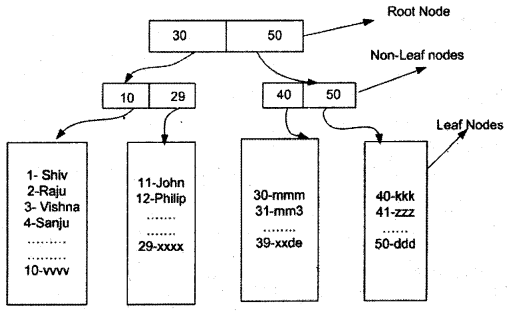
In a Non-Clustered index, the leaf nodes point to pointers (they are rowid’s) which then point to actual data.
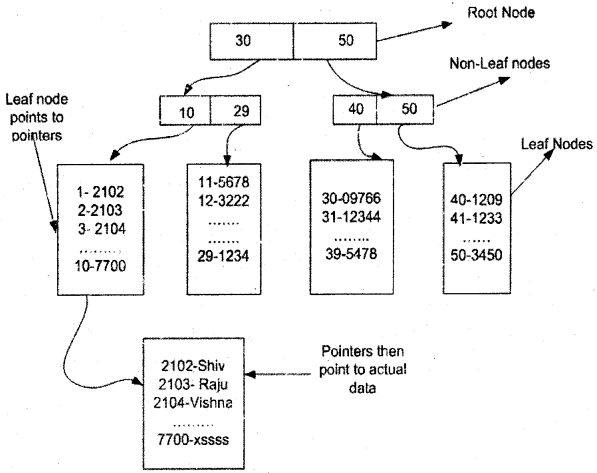
So here’s what the main difference is in clustered and non-clustered , in clustered when we reach the leaf nodes we are on the actual data. In non-clustered indexes we get a pointer, which then points to the actual data.
So after the above fundamentals following are the basic differences between them:-
- Also note in clustered index actual data as to be sorted in same way as the clustered indexes are. While in non-clustered indexes as we have pointers which is logical arrangement we do need this compulsion.
- Sc we can have only’one clustered index on a table as we can nave only one physical order while we can have more than one non-clustered indexes.
Question 6.
If we make non-clustered index on a table which has clustered indexes, how does the architecture change?
Answer:
The only change is that the leaf node point to clustered index key. Using this clustered index key can then be used to finally locate the actual data. So the difference is that leaf node has pointers while in the next half it has clustered keys. So if we create non-clustered index on a table which has clustered index it tries to use the clustered index.
Question 7.
(DB)What is “FillFactor” concept in indexes?
Answer:
When SQL Server creates new indexes, the pages are by default full. “FillFactor” is a percentage value (from 1 – 100) which says how much full your pages will be. By default “FillFactor” value is zero.
Question 8.
(DB) What is the best value for “FillFactor”?
Answer:
“FillFactor” depends on how transactional your database is. Example if your database is highly transactional (i.e. heavy insert’s are happening on the table), then keep the fill factor less around 70. If it’s only a read-only database probably used only for reports you specify 100%.
Remember there is a page split when the page is full. So fill factor will play an important role.
Question 9.
What arc “Index statistics”?
Answer:
Statistics are something the query optimizer will use to decide what type of index (table scan or index scan) to be used to search data. Statistics change according to inserts and updates on the table, nature of data on the table etc…In short “Index statistics” are not same in all situations. So DBA has to run statistics again and again after certain interval to ensure that the statistics are up-to-date with the current data.
Note If you want to create index you can use either the "Create Index" statement or you can use the GUI.
Question 10.
(DB)How can we see the statistics of an index?
Answer:
Twist: – How can we measure the health of the index?
In order to see statistics of any index following the T-SQL command, you will need to run.
Note Before reading this you should have all the answers of the pervious section clear.
Especially about extent, pages and indexes.
DECLARE
@ID int,
@IndexID int,
@IndexName varchar(128)
-- input your table and index name
SELECT @IndexName = ’AK_Department_Name'
SET @ID = OBJECT_ID('HumanResources.Department')
SELECT @IndexID = IndID
FROM sysindexes
WHERE id = @ID AND name = @IndexName
--run the DBCC command
DBCC SHOWCONTIG (@id, @lndexID)
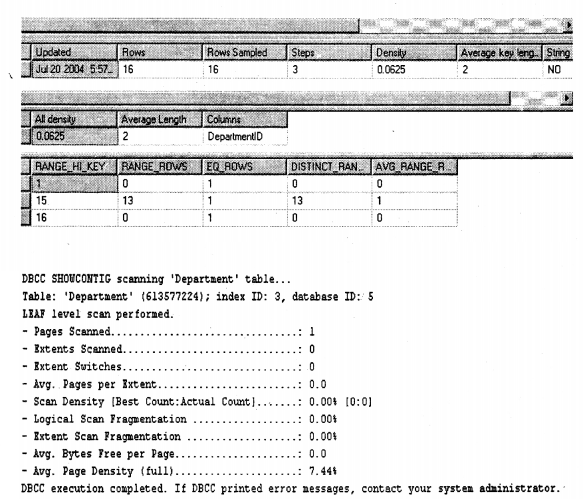
Just a short note here “DBCC” i.e. “Database consistency checker” is used for checking the health of a lot of entities in SQL Server. Now here we will be using it to see index health. After the command is run you will see the following output. You can also run “DBCC SHOWSTATISTICS” to see when was the last time the indexes rebuild.
Pages Scanned
The number of pages in the table (for a clustered index) or index.
Extents Scanned
The number of extents in the table or index. If you remember we had said in the first instance that extent has pages. The more extents for the same number of pages the higher will be the fragmentation.
Extent Switches
The number of times SQL Server moves from one extent to another. More the switches it has to make for the same amount of pages, the more fragmented it is.
Avg. Pages per Extent
The average number of pages per extent. There are eight pages/extent so if you have an extent full with the eight you are in a better position.
Scan Density [Best Count: Actual Count]
This is the percentage ratio of Best count / Actual count. The best count is a number of extent changes when everything is perfect. It’s like a baseline. The actual count is the actual number of extent changes on that type of scenario.
Logical Scan Fragmentation
Percentage of out-of-order pages returned from scanning the leaf pages of an index. An out of order page is one for which the next page indicated is a different page than the page pointed to by the next page pointer in the leaf page.
Extent Scan Fragmentation
This one is telling us whether an extent is not physically located next to the extent that it is logically located next to. This just means that the leaf pages of your index are not physically in order (though they still can be logical), and just what percentage of the extent this problem pertains to.
Avg. Bytes free per page
This figure tells how many bytes are free per page. If it’s a table with heavy inserts or highly transactional then more free space per page is desirable, so that it will have fewer page splits.
If it’s just a reporting system then having this closer to zero is good as SQL Server can then read data with less number of pages.
Avg. Page density (full)
Average page density (as a percentage). It’s is nothing but:-
1 – (Avg. Bytes free per page / 8096)
8096 = one page is equal to 8096 bytes
Note Read every of the above sections carefully, mease you are looking for DBA job you will
need the above'fundamentals to be very clear. Normally interviezver will try to shoot
questions like "Ifyou see the fillfactor is this much, what will you conclude?, If you see
the scan density this much what zvill you conclude?
Question 11.
(DB) How do you reorganize your index, once you find the problem?
Answer:
You can reorganize your index using “DBCC DBREINDEX”. You can either request a particular index to be re-organized or just re-index all indexes of the table.
This will re-index your all indexes belonging to the "HumanResources.Department".
DBCC DBREINDEX ([HumanResources.Department])
This will re-index only "AK__Depart.mentr.Name".
DBCC DBREINDEX ([HumanResources.Department] , [AK_Department_Name])
This will re-index with a "fill factor".
DBCC DBREINDEX ([HumanResources.Department],[AK_Department_Name], 70)
You can then again run DBCG SHOWCONTIG to see the results.
Question 12.
What is Fragmentation?
Answer:
Speed issues occur because of two major things
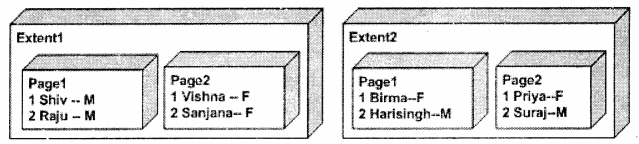
Splits have been covered in the first questions. But one other big issue is fragmentation. When the database grows it will lead to splits, but what happens when you delete something from the database…hehehe life has a lot of turns right. Ok, let’s say you have two extents and each has two pages with some data. Below is a graphical representation. Well actually that’s now how things are inside but for sake of clarity lot of things have been removed.
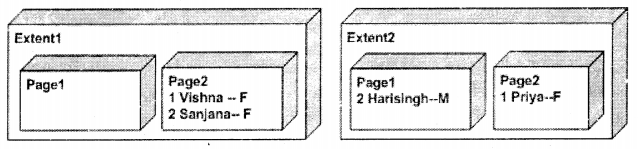
Now over a period of time some Extent and Pages data undergo some delete. Here’s the modified database scenario. Now one observation you can see is that some pages are not removed even when they do not have data. Second If SQL. the server wants to fetch all “Females” it has to span across to two extents and multiple pages within them. This is called “Fragmentation” i.e. to fetch data you span across a lot of pages and extents. This is also termed “Scattered Data”.
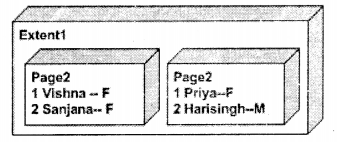
What if the fragmentation is removed, you only have to search in two extant and two pages. Definitely, this will be faster as we are spanning across fewer entities.
Question 13.
(DB)How can we measure Fragmentation?
Answer:
Using “DBCC SHOWCONTIG
Question 14.
(DB)How can we remove the Fragmented spaces?
Answer:
- Update Statistics The most used way by DBA’s
- Sp_updatestats. It’s the same as update statistics, but update statistics applies only for specified objects and indexes, while “sp_updatestats” loops through all tables and applies statistics updates to each and every table. Below is a sample that is run on the “AdventureWorks” database.
Note "AdventureWorks" is a sample database that is shipped with SQL Server2005.
- DBCC INDEXFRAG: – This is not the effective way of doing fragmentation it only does fragment on the leaf nodes.
Question 15.
What are the criteria you will look into while selecting an index?
Answer:
Note Some answers what I have got for this question.
1. I will create an index wherever possible.
2. I will create clustered index on every table.
That’s why DBA’s are always needed.
3. How often the field is used for selection criteria. For example, in a “Customer” table
you have “CustomerCode” and “PinCode”. Most of the searches are going to be performed on “CustomerCode” so it’s a good candidate for indexing rather than using “PinCode”. In short, you can look into the “WHERE” clauses of SQL to figure out if it’s the right choice for indexing.
4. If the column has a higher level of unique values and is used in selection criteria again is a valid member for creating indexes.
5. If the “Foreign” key of the table is used extensively in Joins (Inner, Outer, and Cross) again a good member for creating indexes.
6. If you find the table to be highly transactional (huge insert, update, and deletes) probably not a good entity for creating indexes. Remember the split problems with Indexes.
7. You can use the “Index tuning wizard” for index suggestions.
Question 16.
(DB)What is “Index Tuning Wizard”?
Answer:
Twist: – What is “Work Load File”?
In the previous question, the last point was using the “Index Tuning wizard”. You can get the “Index Tuning Wizard” from “Microsoft SQL Server Management Studio” – “Tools” – “SQL Profiler”.
Note This book refers to SQL Server 2005, so probably if you have SQL Server 2000 installed you will
get the SQL Profiler in Start - Programs - Microsoft SQL Server -- Profiler. But in this whole book,
we will refer only to SQL Server 2005. We will go step by step for this answer explaining how exactly
"Index Tuning Wizard" can be used.
Ok before we define any indexes let’s try to understand what is “Work Load File”. “Work Load File” is the complete activity that has happened on the server for a specified period of time. All the activity is entered into a “.trc” file which is called “Trace File”. Later “Index Tuning Wizard” runs on the “Trace File” and on every query fired it tries to find which columns are valid candidates for indexes depending on the Indexes.
Following are the step’s to use “Index Tuning Wizard”:-
- Create the Trace File using “SQL Profiler”.
- Then use “Database Tuning Advisor” and the “Trace File” for what columns to be indexed.
Create Trace File
Once you have opened the “SQL Profiler” click on “New Trace”.
It will alert for giving you to all trace file details for instance the “Trace Name”, “File where to save”. After providing the details click on the “Run” button provided below. I have provided the file name of the trace file as the “Testing.trc” file.
HUH and the action starts. You will notice that profiler has started tracing queries that are hitting “SQL Server” and logging all those activities in to the “Testing.trc” file. You also see the actual SQL and the time when the SQL was fired.
Let the trace run for some bit of time. In an actually practical environment, I run the trace for almost two hours at peak to capture the actual load on the server. You can stop the trace by clicking on the red icon given above.
You can go to the folder and see your “.trc” file created. If you try to open it in notepad you will see binary data. It can only be opened using the profiler. So now that we have the load file we have to just say to the advisor, hey advisor here’s my problem (trace file) can you suggest to me some good indexes improve my database performance.
Using Database Tuning Advisor
In order to go to “Database Tuning Advisor,” you can go from “Tools” – “Database Tuning Advisor”.
In order to supply the workload file, you have to start a new session in “Database tuning advisor”.
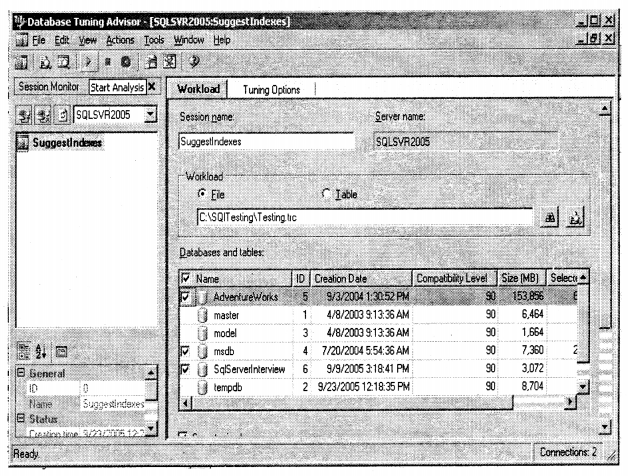
After you have said “New Session” you have to supply all details for the session. There are two primary requirements you need to provide to the Session:-
- Session Name
- “Work Load File” or “Table” (Note you can create either a trace file or you can put it in SQL Server table while running the profiler).
I have provided my “Testing.trc” file which was created when I ran the SQL profiler. You can also filter for which database you need index suggestions. At this moment I have checked all the databases. After all the details are filled in you have to click on the “Green” icon with the arrow. You can see the tooltip as “Start analysis” in the image below.
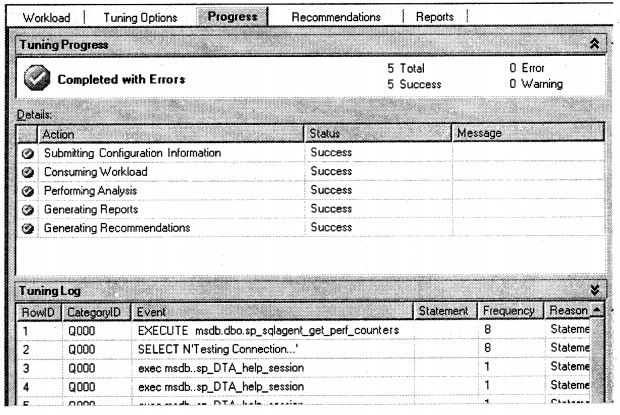
While analyzing the trace file it performs basic four major steps:-
- Submits the configuration information.
- Consumes the Workload data (that can be in the format of a file or a database table).
- Start performing analysis on all the SQL executed in the trace file.
- Generates reports based on analysis.
- Finally give the index recommendations.
You can see all the above steps have run successfully which is indicated by “0 Error and 0 Warning”.
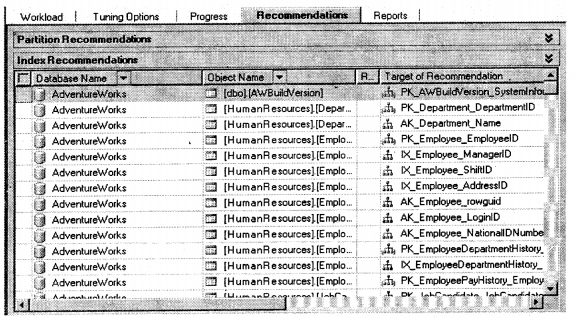
Now it’s time to see what index recommendations SQL Server has provided us. Also, note it has included two new tabs after the analysis was done “Recommendations” and “Reports”.
You can see on “AdventureWorks” SQL Server has given me huge recommendations. Example on “HumanResources.Department” he has told me to create an index on “PK_Department_DepartmentId”.
In case you want to see detailed reports you can click on the “Reports” tab and there is a wide range of reports which you can use to analyze how your database is performing on that “Work Load” file.
Note The whole point of putting this alt step by step was that you have a complete understanding
of how to do automatic index decisions " using SQL Server. During the interview one of the questions's
that is very sure "How do you increase speed performance of SQL Server? "and talking about the "index
Tuning Wizard" can fetch you some decent points.
Question 17.
(DB)What is an Execution Plan?
Answer:
The execution plan gives how the query optimizer will execute a give SQL query. Basically, it shows the complete plan of how SQL will be executed. The whole query plan is prepared to depend on a lot of data for instance:-
- What type of indexes do the tables in the SQL have?
- Amount of data.
- Type of joins in SQL (Inner join, Left join, Cross join, Right join, etc)
Click on the ICON in SQL Server management studio as shown in the figure below.

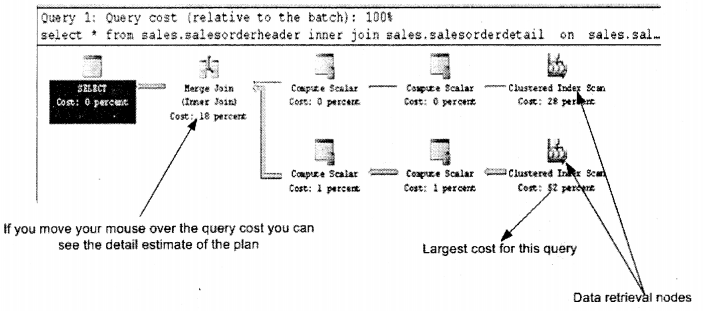
In the bottom window pane, you will see the complete breakup of how your SQL Query will execute. Following is the way to read it:-
- Data flows from left to right.
- Any execution plan sums to a total of 100 %. For instance in the below figure it is 18 + 28 + 1 + 1 + 52. So the highest is taken by Index scan 52 percent. Probably we can look into that logic and optimize this query.
- Right, most nodes are actually data retrieval nodes. I have shown them with arrows the two nodes.
- In the below figure you can see some arrows are thick and some are thin. The more thickness more the data is transferred.
- There are three types of join logic nested join, hash join and merge join.
If you move your mouse gently over any execution strategy you will see a detail breakup of how that node is distributed.
Question 18.
How do you see the SQL plan in textual format?
Answer:
Execute the following “set showplan_text on” and after that execute your SQL, you will see a textual plan of the query. In the first question what I discussed was a graphical view of the query plan. Below is a view of how a textual query plan looks like. In older versions of SQL Server where there was no way of seeing the query plan graphically “SHOWPLAN” was the most used. Today if any one is using it then I think he is doing a show business or a newcomer learner.
Question 19.
(DB)What is nested join, hash join, and merge join in SQL Query plan?
Answer:
A join is whenever two inputs are compared to determine an output. There are three basic types of strategies for this and they are: nested loops join, merge join and hash join. When a join happens the optimizer determines which of these three algorithms is best to use for the given problem, however, any of the three could be used for any join. All of the costs related to the join are analyzed the most cost-efficient algorithm is picked for use. These are in-memory loops used by SQL Server.
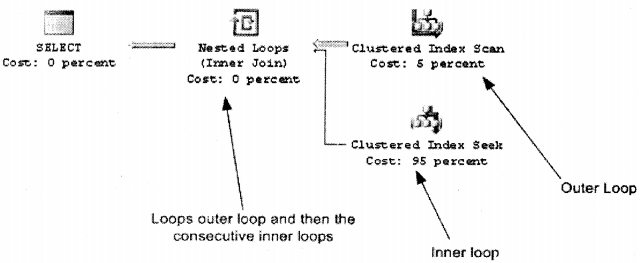
Nested Join
If you have less data this is the best logic. It has two loops one is outer and the other is the inner loop. For every outer loop, its loops through all records in the inner loop. You can see the two-loop inputs given to the logic. The top index scan is the outer loop and the bottom index seek is the inner loop for every outer record.

It’s like executing the below logic:-
For each outer records
For each inner records
Next
Next
So you visualize that if there fewer inner records this is a good solution.
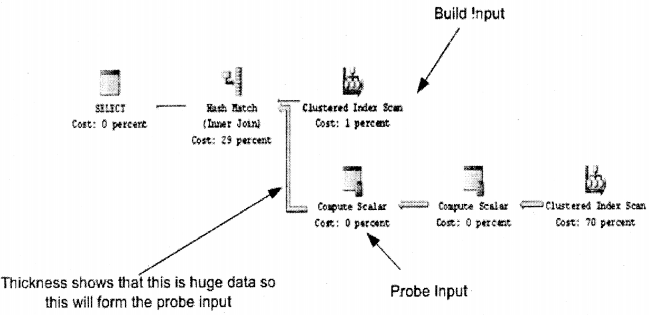
Hash Join
Hash join has two inputs “Probe” and “Build” input. First, the “Build” input is processed, and then the “Probe” input. Every input that is smaller is the “Build” input. SQL Server first builds a hash table using the build table input. After that, he loops through the probe input and finds the matches using the hash table created previously using the build table and does the processing and gives the output.
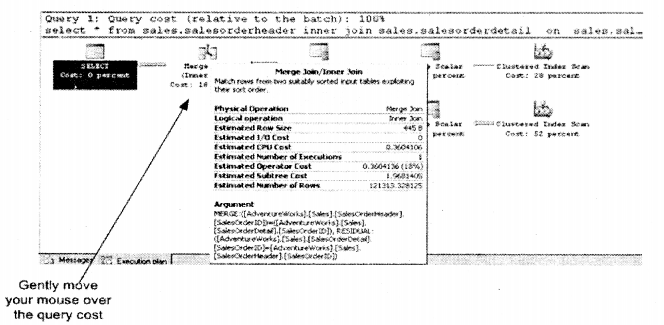
Merge Join
In merge joins both the inputs are sorted on the merge columns. Merge columns are determined depending on the inner join defined in SQL. Since each input join is sorted merge join takes input and compares for equality. If there is equality then a matching row is produced. This is processed till the end of rows.
Question 20.
What joins are good in what situations?
Answer:
Nested joins are best suited if the table is small and it’s a must the inner table should have an index.
Merge joins best of large tables and both tables participating in the joins should have indexes.
Hash joins best for small outer tables and large inner tables. Not necessary that tables should have indexes, but would be better if the outer table has indexed.
Note Previously we have discussed table scan and index scan do revise it which is also important
from the aspect of reading query plan.
Question 21.
(DB)What is RAID and how does it work ?
Answer:
Redundant Array of Independent Disks (RAID) is a term, used to describe the technique of j improving data availability through the use of arrays of disks and various data-striping , methodologies. Disk arrays are groups of disk drives that work together to achieve higher ? data-transfer and I/O rates than those provided by single large drives. An array is a set of multiple disk drives plus a specialized controller (an array controller) that keeps track of _ how data is distributed across the drives. Data for a particular file is written in segments to the different drives in the array rather than being written to a single drive.
For speed and reliability, it’s better to have more disks. When these disks are arranged in j certain patterns and use a specific controller, they are called a Redundant Array of Inexpensive Disks (RAID) set. There are several numbers associated with RAID, but the most common are 1, 5 and 10.
% RAID 1 works by duplicating the same writes on two hard drives. Let’s assume you have ^ two 20 Gigabyte drives. In RAID 1, data is written at the same time to both drives. RAID1 is optimized for fast writes. ”
RAID 5 works by writing parts of data across all drives in the set (it requires at least three drives). If a drive failed, the entire set would be worthless. To combat this problem, one of the drives stores a “parity” bit. Think of a math problem, such as 3 + 7 = 10. You can think , of the drives as storing one of the numbers, and the 10 is the parity part. By removing any – one of the numbers, you can get it back by referring to the other two, like this: 3 + X = 10. Of course, losing more than one could be evil. RAID 5 is optimized for reads.
RAID 10 is a bit of a combination of both types. It doesn’t store a parity bit, so it’s fast, but it duplicates the data on two drives to be safe. You need at least four drives for RAID 10. This type of RAID is probably the best compromise for a database server.
Note It’s difficult to cover complete aspect of RAID in this book.lt’s better to take some decent SQL SER VER book for in detail knowledge, but yes from interview aspect you can probably escape with this answer.