

Scrape wikipedia: We are going to make a scraper which will scrape the wikipedia page.
The scraper will get directed to the wikipedia page and then it will go to the random link.
I guess it will be fun looking at the pages the scraper will go.
Setting up the scraper:
Wikipedia web scraping: Here, I will be using Google Colaboratory, but you can use Pycharm or any other platform you want to do your python coding.
I will be making a colaboratory named Wikipedia. If you will use any python platform then you need to create a .py file followed by the any name for your file.
To make the HTTP requests, we will be installing the requests module available in python.
- Web crawling and scraping in Python
- Building an RSS feed Scraper with Python
- Python Project Ideas & Topics for Beginners to Try in 2021 | Interesting Python Projects List for Beginners, Intermediate, Advanced Level Students
Pip install requests
Web scraping wikipedia: We will be using a wiki page for the starting point.
Import requests
Response = requests.get(url = “https://en.wikipedia.org/wiki/Web_scraping”)
print(response.status_code)
When we run the above command, it will show 200 as a status code.

Okay!!! Now we are ready to step on the next thing!!
Extracting the data from the page:
We will be using beautifulsoup to make our task easier. Initial step is to install the beautiful soup.
Pip install beautifulsoup4
Beautiful soup allows you to find an element by the ID tag.
Title = soup.find( id=”firstHeading”)
Bringing everything together, our code will look like:
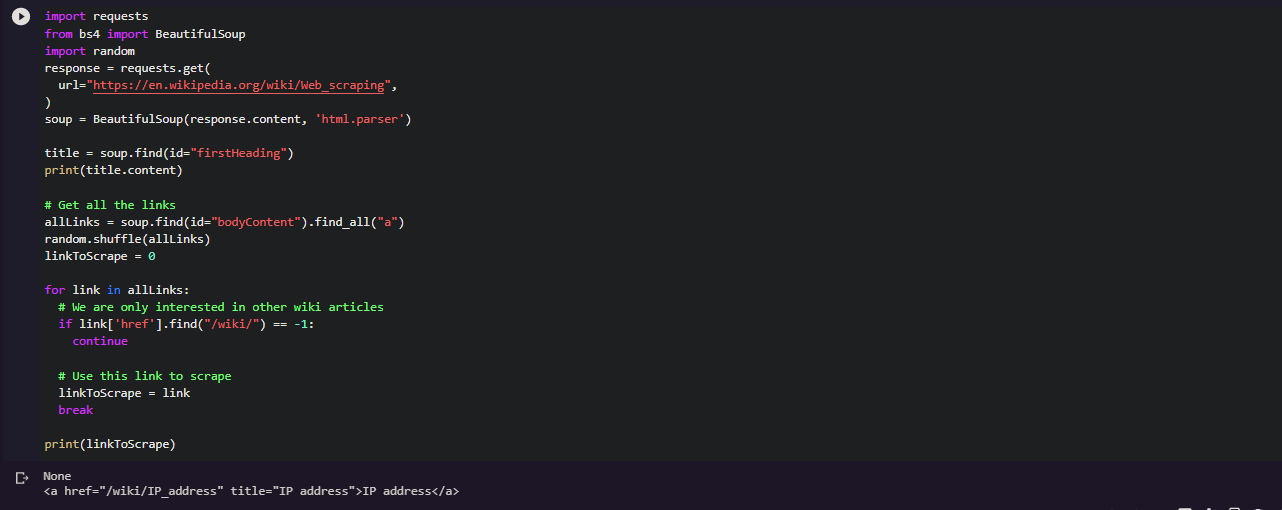
As we can see, when the program is run, the output is the title of the wiki article i.e Web Scraping.
Scraping other links:
Other than scraping the title of the article, now we will be focusing on the rest of the things we want.
We will be grabbing <a> tag to another wikipedia article and scrape that page.
To do this, we will scrape all the <a> tags within the article and then I will shuffle it.
Do not forget to import the random module.
You can see, the link is directed to some other wikipedia article page named as IP address.
Creating an endless scraper:
Now, we have to make the scraper scrape the new links.
For doing this, we have to move everything into scrapeWikiArticle function.
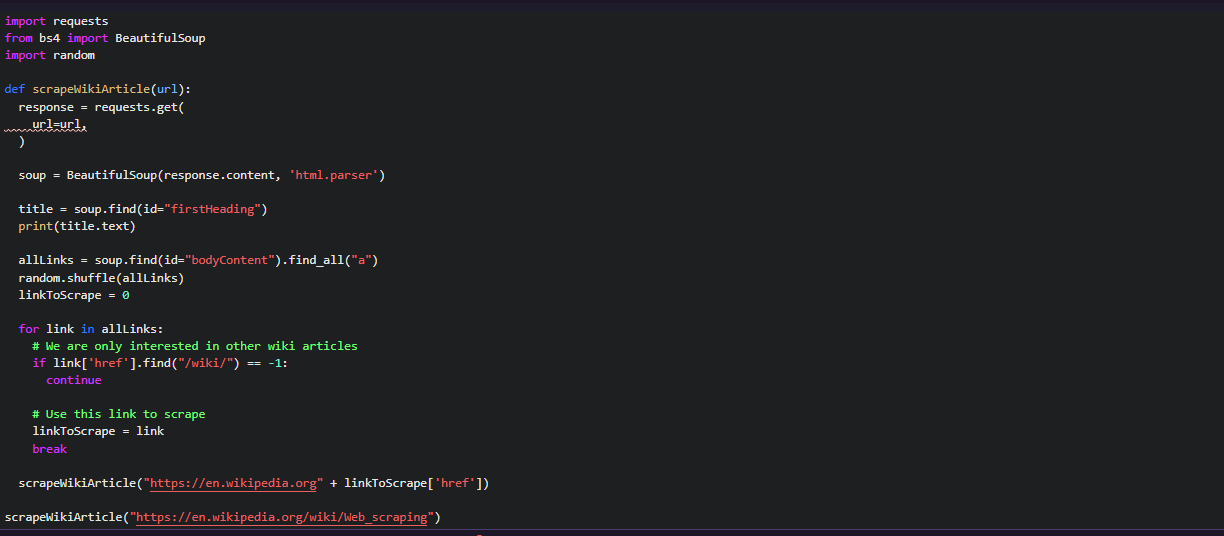
The function scrapeWikiArticle will extract the links and and title. Then again it will call this function and will create an endless cycle of scrapers that bounce around the wikipedia.
After running the program, we got:

Wonderful! In only few steps, we got the “web scraping” to “Wikipedia articles with NLK identifiers”.
Conclusion:
We hope that this article is useful to you and you learned how to extract random wikipedia pages. It revolves around wikipedia by following random links.