

Amazon scraping python: Will it not be good if all the information related to some product will be placed in only one table? I guess it will be really awesome and accessible if we can get the entire information at one place.
Since, Amazon is a huge website containing millions of data so scraping the data is quite challenging. Amazon is a tough website to scrape for beginners and people often get blocked by Amazon’s anti-scraping technology.
In this blog, we will be aiming to provide the information about the scrapy and how to scrape the Amazon website using it.
What is Scrapy?
Scrapy is a free and open-source web-crawling Python’s framework. It was originally designed for web scraping, extracting the data using API’s and or general-purpose web crawler.
This framework is used in data mining, information processing or historical archival. The applications of this framework is used widely in different industries and has been proven very useful. It not only scrapes the data from the website, but it is able to scrape the data from the web services also. For example, Amazon API, Facebook API, and many more.
How to install Scrapy?
Firstly, there are some third-party softwares which needs to be installed in order to install the Scrapy module.
- Python: As Scrapy has the base of the Python language, one has to install it first.
- pip: pip is a python package manager tool which maintains a package repository and installs python libraries, and its dependencies automatically. It is better to install pip according to system OS, and then try to follow the standard way of installing Scrapy.
There are different ways in which we can download Scrapy globally as well as locally but the most standard way of downloading it is by using pip.
- Web crawling and scraping in Python
- Python : How to Unpack List, Tuple or Dictionary to Function arguments using * and **
- How to web scrape with Python in 4 minutes
Run the below command to install Scrapy using pip:
Pip install scrapy
How to get started with Scrapy?
Since we know that Scrapy is an application framework and it provides multiple commands to create an application and use them. But before everything, we have to set up a new Scrapy project. Enter a directory where you’d like to store your code and run:
Scrapy startproject new_project
This will create a directory:
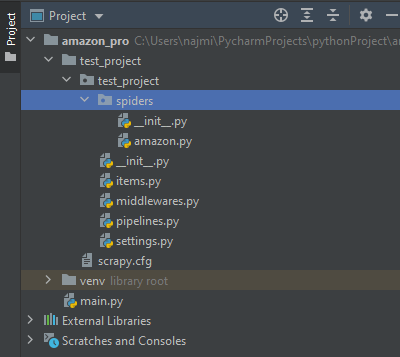
Scrapy is an application framework which follows object oriented programming style for the definition of items and spiders for overall applications.
The project structure contains different the following files:
- Scrapy.cfg : This file is a root directory of the project, which includes project name with the project settings.
- Test_project : It is an application directory with many different files which actually make running and scraping responsible from the web URLs.
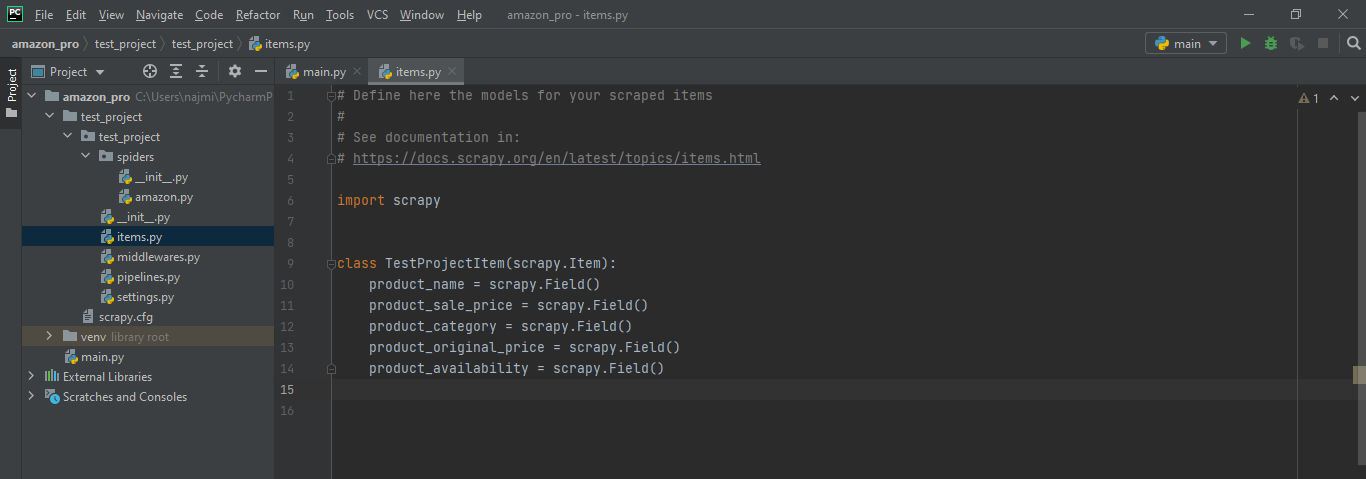
- Items.py :Items are containers that will be loaded with the scraped data and they work like simple python dictionaries.Items provide additional prevention against typos and populating undeclared fields.
- Pipelines.py :After the scraping of an item has been done by the spider, it is sent to the item pipeline which processes it through several components. Each class has to implement a method called process_item for the processing of scraped items.
- Settings.py : It allows the customization of the behaviour of all scrapy components, including the core, extensions, pipelines, and spiders themselves.
- Spiders : It is a directory which contains all spiders/crawlers as python classes.
Scrape Amazon Data: How to Scrape an Amazon Web Page
For a better understanding of how the scrapy works, we will be scraping the product name, price, category, and it’s availability from the Amazon.com website.
Let’s name this project amazon_pro. You can use the project name according to your choice.
Start by writing the below code:
Scrapy startproject test_project
The directory will be created in the local folder by the name mentioned above.
Now we need three things which will help in the scraping process.
- Update items.py field which we want to scrape. For example names, price, availability, and so on.
- We have to create a new spider with all the necessary elements in it like allowed domains, start_urls and parse method.
- For data processing, we have to update pipelines.py file.
Now after creating the spider, follow thee further steps given in the terminal:
- Scrapy genspider amazon amazon.com
Now, we need to define the name, URLs, and possible domains to scrape the data.
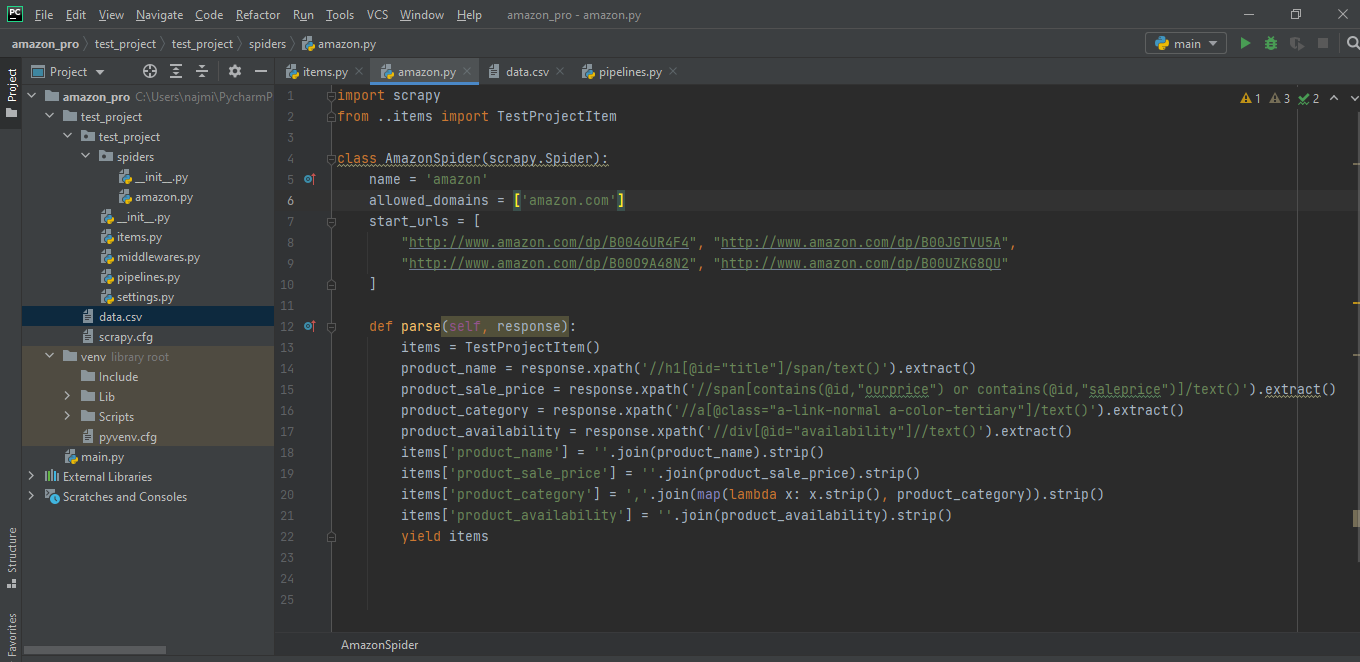
An item object is defined in the parse method and is filled with required information using the utility of XPath response object. It is a search function that is used to find elements in the HTML tree structure. Lastly let’s yield the items object, so that scrapy can do further processing on it.
Next, after scraping data, scrapy calls Item pipelines to process them. These are called Pipeline classes and we can use these classes to store data in a file or database or in any other way. It is a default class like Items that scrapy generates for users.
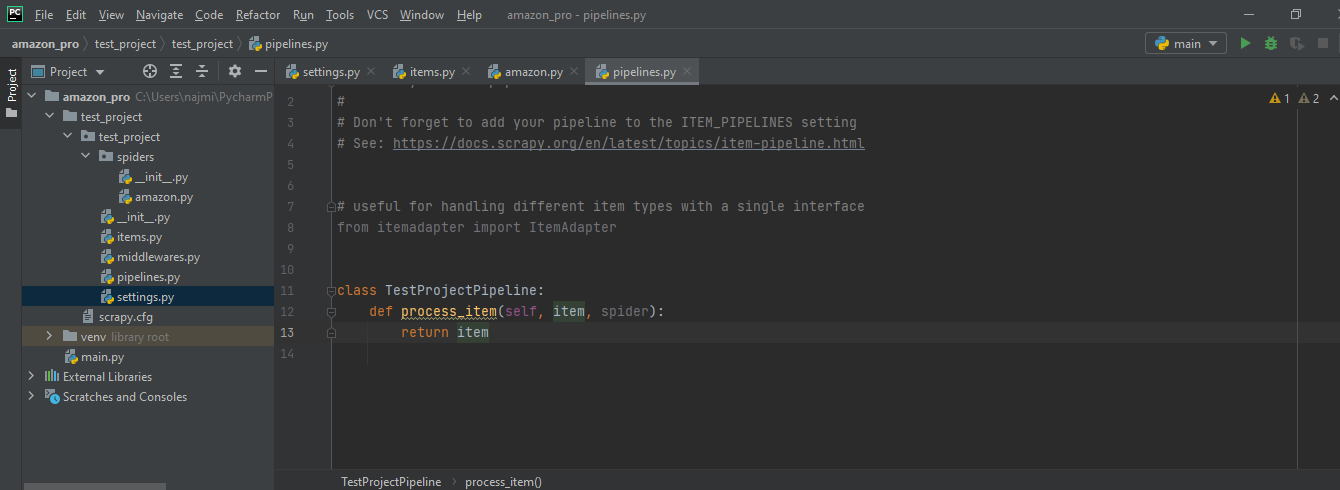
The process_item is implemented by the pipeline classes method and items are being yielded by a Spider each and every time. It takes the item and spider class as arguments and returns a dict object. So for this example, we are just returning item dict as it is.
Now, we have to enable the ITEM_PIPELINES from settings.py file.
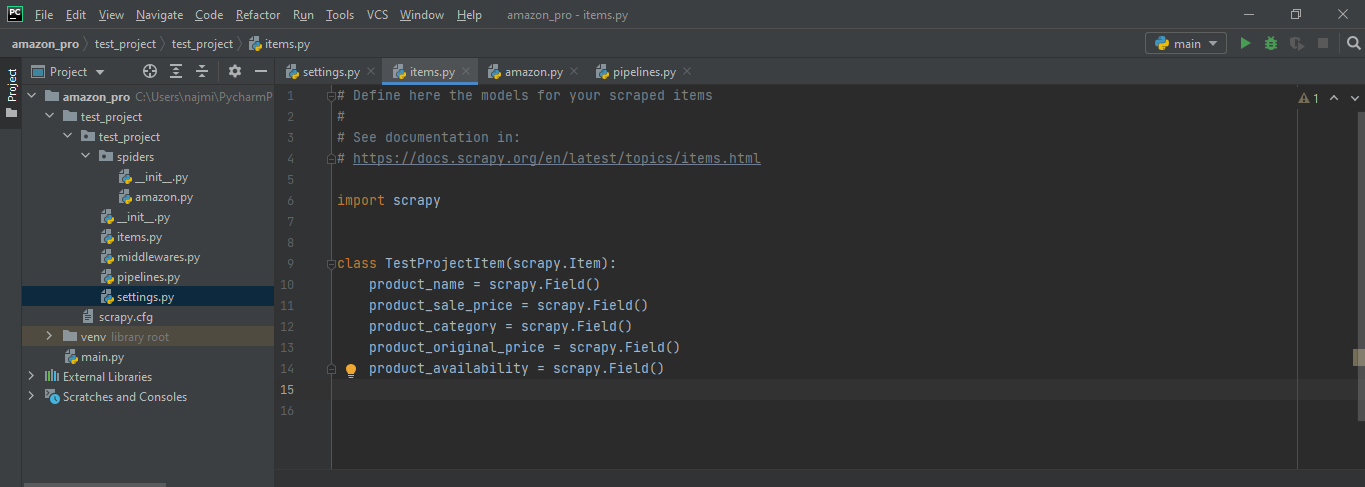
Now, after completing the entire code, we need to scrape the item by sending requests and accepting response objects.
We will call a spider by its unique name and scrapy will easily search from it.
Scrapy crawl amazon
Now, after the items have been scraped, we can save it to different formats using their extensions. For example, .json, .csv, and many more.
Scrapy crawl amazon -o data.csv
The above command will save the scraped data in the csv format in data.csv file.
Here is the output of the above code:
[
{"product_category": "Electronics,Computers & Accessories,Data Storage,External Hard Drives", "product_sale_price": "$949.95", "product_name": "G-Technology G-SPEED eS PRO High-Performance Fail-Safe RAID Solution for HD/2K Production 8TB (0G01873)", "product_availability": "Only 1 left in stock."},
{"product_category": "Electronics,Computers & Accessories,Data Storage,USB Flash Drives", "product_sale_price": "", "product_name": "G-Technology G-RAID with Removable Drives High-Performance Storage System 4TB (Gen7) (0G03240)", "product_availability": "Available from these sellers."},
{"product_category": "Electronics,Computers & Accessories,Data Storage,USB Flash Drives", "product_sale_price": "$549.95", "product_name": "G-Technology G-RAID USB Removable Dual Drive Storage System 8TB (0G04069)", "product_availability": "Only 1 left in stock."},
{"product_category": "Electronics,Computers & Accessories,Data Storage,External Hard Drives", "product_sale_price": "$89.95", "product_name": "G-Technology G-DRIVE ev USB 3.0 Hard Drive 500GB (0G02727)", "product_availability": "Only 1 left in stock."}
]
We have successfully scraped the data from Amazon.com using scrapy.