HTML5 css3 interview questions: HTML is an important language and learning it will definitely land you with plenty of opportunities. The latest version of HTML is HTML5. We have compiled the most frequently asked HTML5 and CSS3 .NET Interview Questions which will help you with different expertise levels. Use them as a quick reference to test your knowledge of the concepts of HTML5 and CSS3 and improves on the areas of need.
.NET Interview Questions on HTML 5 and CSS 3
Question 1.
What is the relationship between SGML, HTML, XML and HTML?
Answer:
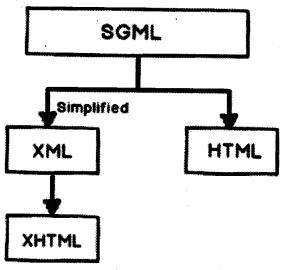
SGML (Standard Generalized Markup Language) is a standard which tells how to specify document markup. It is only a Metalanguage that describes how a document markup should be. HTML is a markup language that is described using SGML.
So by SGML, they created DTD (Document Type Definition) which the HTML refers to and needs to adhere to the same. So you will always find the “DOCTYPE” attribute at the top of the HTML page which defines which DTD is used for parsing purposes.
<!DOCTYPE html PUBLIC “-//W3C//DTD HTML 4.01//EN”
“http: //www. w3. org/TR/html4/strict. dtd”>
Now parsing SGML was a pain so they created XML to make things better. XML uses SGML. For example, in SGML you have to start and end tags but in XML you can have closing tags that close automatically (“</customer>”).
XHTML (extensible HyperText Markup Language) was created from XML which was used in HTML 4.0. So for example in SGML derived HTML “</br>” is not valid but in XHTML it’s valid. You can refer XML DTD as shown in the below code snippet.
<!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN”
“http: //www. w3. org/TR/xhtml 1/D TD/xhtml1 -transitional. dtd">
In short SGML is the parent of every one as shown in Figure 9.1. Older HTML utilizes SGML and HTML 4.0 uses XHTML which derived from XML.
Question 2.
What is HTML 5?
Answer:
HTML 5 is a new standard for HTML whose main target is to deliver everything without the need for any additional plugins like Flash, Silverlight, etc. It has everything from animations, videos, rich GUI, etc.
HTML5 is a cooperation output between World Wide Web Consortium (W3C) and the Web HyperText Application Technology Working Group (WHATWG).
Question 3.
In HTML 5 we do not need DTD why?
Answer:
HTML 5 does not use SGML or XHTML it is completely a new thing so you do not need to refer to DTD. For HTML 5 you just need to put the below DOCTYPE code which makes the browser identify that this is an HTML 5 document.
<!DOCTYPE html>
Question 4.
If I do not put <! DOCTYPE html> will HTML 5 work?
Answer:
No, the browser will not be able to identify that it’s an HTML document and HTML 5 tags will not function properly.
Question 5.
Which browsers support HTML 5?
Answer:
Almost all browsers, i.e., Safari, Chrome, Firefox, Opera, Internet Explorer, support HTML 5.
Question 6.
How is the page structure of HTML 5 different from HTML 4 or previous HTML?
Answer:
A typical Web page has headers, footers, navigation, central area, and sidebars (as shown in Figure 9.2). Now if we want to represent the same in HTML 4 with proper names to the HTML section we would probably use a div tag.
But in HTML 5 they have made it more clear by creating element names for those sections which makes your HTML more readable.
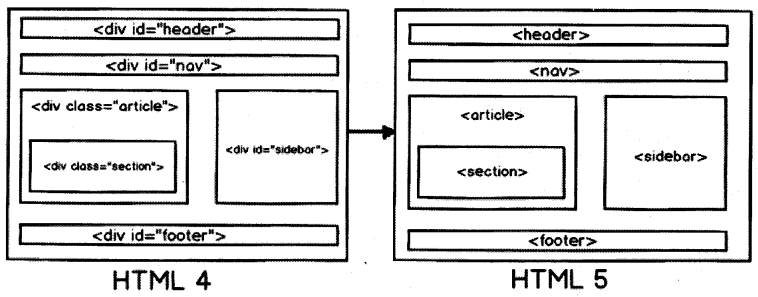
Below are more details of the HTML 5 elements which form the page structure.
- <header>: Represents header data of HTML.
- <footer>: Footer section of the page.
- <nav>: Navigation elements in the page.
- <article>: Self-contained content.
- <section>: Used inside article to define sections or group content in to sections.
- <aside>: Represent side bar contents of a page.
HTML5 and CSS3 Interview Questions
Question 7.
What is datalist in HTML 5?
Answer:
Datalist element in HTML 5 helps to provide auto-complete feature in a textbox as shown in Figure 9.3.

Below is the HTML code for datalist feature.
<input list=”Country”>
<datalist id=”Country”>
<option value=”India”>
<option value=”Italy”>
<option value=”Iran”>
<option value=”Israel”>
<option value=”Indonesia”>
</datalist>
Question 8.
What are the different new form element types in HTML 5?
Answer:
There are ten important new form elements introduced in HTML 5:
- Color
- Date
- Datetime-local
- Email
- Time
- URL
- Range
- Telephone
- Number
- Search
Let’s understand these elements step-by-step.
If you want to show a color picker dialog box (See Figure 9.4).
<input type=”color” name=favcolor”>

If you want to show calendar dialog box (see Figure 9.5)
<input type="date" name="bday">
If you want to show a calendar with local time (See Figure 9.6).
<input type=”DateTime-local” name=”daytime”>
If you want to create an HTML text with e-mail validation we can set the type as “email”.
<input type=’’email” name=”email”>

For URL validation set the type as “url” as shown in the Figure 9.8 in which HTML code is given.
<input type=”url” name=”sitename’>
For URL validation set the type as “url” as shown in the below HTML code.

If you want to display textbox with number range you can set type to number (See Figure 9.9).
<input type=”number” name=”quantity” min=”1" max=”5">
If you want to display a range control you can use type as range as shown in code given below (see Figure 9.10)
<input type="range" min="0" max="10" step="2" value="6">

Want to make textbox as search engine box.
<input type="search" name="googlengine">
Want to only take time input.
<input type-time” name=”usr_time”>
If you want to make textbox to accept telephone numbers.
<input type=”tel” name=”mytel”>
Question 9.
What is output element in HTML 5?
Answer:
Output element is needed when you need calculation from two inputs to be summarized into a label. For instance, you have two textboxes as shown in Figure 9.11 and you want to add numbers from these textboxes and send them to a label.

Below goes the code of how to use output element with HTML 5.
<form onsubmit="return false" oninput="o.value = parselnt(a.value) + parseInt(b.value)">
<input name="a" type="number"> +
<input name="b" type="number"> =
<output name="o"></output>
</form>
You can also replace “parselnt” with “valueAsNumber” for simplicity. You can also use “for” in the output element for more readability.
<output name=”o"for=”a b”></output>
Question 10.
What is SVG?
Answer:
SVG stands for Scalable Vector Graphics. It is a text-based graphics language that draws images using text, lines, dots, etc. This makes it lightweight and renders it faster.

Top HTML5 and CSS3 Questions and Answers
Question 11.
Can we see a simple example of SVG using HTML 5?
Answer:
Let’s say we want to display as shown in Figure 9.12 simple line using HTML 5 SVG.
Below is how the code of HTML 5. You can see the SVG tag which encloses the polygon tag for displaying the star image.

<svg id="svgelem" height="200" xmlns="HTTP: //
www.w3.org/2000/svg">
<line x1="0" y1="0" x2="200” y2 = "100"
style="stroke: red;stroke-width: 2"/>
< / svg>
Question 12.
What is the canvas in HTML 5?
Answer:
Canvas is an HTML area in which you can draw graphics.
Question 13.
So how can we draw a simple line on Canvas?
Answer:
- Define the Canvas area.
- Get access to the canvas context area.
- Draw the graphic.
Define the canvas area
So to define the canvas area you need to use the below HTML code. This defines the area on which you can draw.
<canvas id=”mycanvas” width=”600M height=”500” style-’border: 1px solid #000000;”></canvas>
Get access to canvas area
To draw on the canvas area we need to first get reference of the context section. Below is the code for canvas section.
varc=document.getElementByld(“mycanvas”);
var ctx=c. getContext(“2d’);
Draw the graphic
Now once you have access to the context object we can start drawing on the context. So first call the “moveTo” method and start from a point, use lineTo method and draw the line and then apply stroke over it.
ctx.moveTo(10, 10);
ctx.lineTo(200, 100);
ctx.stroke( );
Below is the complete code.
<body onload="DrawMe( );">
<canvas id="mycanvas" width="600" height="500" style="border: 1px solid
#000000;"></canvas>
</body>
<script>
function DrawMe( )
{
var c=document.getElementByld("mycanvas");
var ctx=c.getContext("2d");
ctx.moveTo(10, 10);
ctx.lineTo(200, 100);
ctx.stroke();
}
You should get the as shown in Figure 9.12 output.
Question 14.
What is the difference between Canvas and SVG graphics?
Answer:
Note: If you see the previous two questions both canvas and SVG can draw graphics on the browser.
So in this question interviewer wants to know when will you use what.
| SVG |
Canvas |
| Here’s it’s like draw and remember. In other words any shape drawn by using SVG can be remembered and manipulated, and browser can render it again. |
Canvas is like draw and forget. Once something is drawn you cannot access that pixel and manipulate it. |
| SVG is good for creating graphics like CAD (Computer Aided Design) software where once something is drawn the user wants to manipulate it. |
Canvas is good for draw and forget scenarios likeanimation and games. |
| This is slow as it needs to remember the coordinates for later manipulations. |
This is faster as there is no intention of remembering things later. |
| We can have event handler associated with the drawing object. |
Here we cannot associate event handlers with drawing objects as we do not have references for them. |
| Resolution independent. |
Resolution dependent. |
Question 15.
How to draw a rectangle using Canvas and SVG using HTML 5?
Answer:
HTML 5 code Rectangle code using SVG.
<svg xmlns="HTTP: //www.w3.org/2000/svg" version="1.1">
<rect width="300" height="100"
style="fill: rgb(0, 0, 255);stroke-width: l;stroke: rgb(0, 0, 0)"/>
</svg>
HTML 5 Rectangle code using canvas.
var c=document.getElementByld("myCanvas");
var ctx=c.getContext("2d");
ctx.rect(20, 20, 150, 100);
ctx. stroke ( ) ;
<svg xmlns=''HTTP: //www. w3 . org/2000/svg" version=" 1.1">
<circle cx="100" cy="50" r="40" stroke="black"
stroke-width="2" fill="red"/>
</svg>
var canvas = document.getElementByld('myCanvas');
var context = canvas.getContext('2d');
var centerX = canvas.width / 2;
var centerY = canvas.height / 2;
var radius = 70;
context.beginPath( );
context.arc(centerX, centerY, radius, 0, 2 * Math.PI, false);
context. fillStyle = 'green';
context .fill ( );
context.lineWidth = 5;
context.strokeStyle = '#003300';
context.stroke();
<!DOCTYPE html>
<html>
<body onload="DrawMe( );">
<svg width="500" height="100">
<circle id="circlel" cx="20" cy="20" r="10"
style="stroke: none; fill: #ff0000;"/>
</svg>
</body>
<script>
var timerFunction = setlnterval(DrawMe, 20);
alert("ddd");
function DrawMe( )
{
var circle = document.getElementByld("circle1")
var x = circle.getAttribute("cx");
var newX = 2 + parselnt(x);
if(newX > 500)
{
newX = 20;
}
circle.setAttribute("cx" , newX);
}
</script>
</html>
Using jQuery
var timerFunction = setlnterval(DrawMe, 20);
function DrawMe( )
{
var circle = $("#circlel");
alert("ddd");
var x = circle.attr("cx");
alert("ddd1");
var newX = 2 + parselnt(x);
if (newX > 500)
{
newX = 20;
}
circle.attr("cx", newX);
}
</script>
Move a circle
<svgid="svg1"xmlns="HTTP: //www.w3.org/2000/svg">
<circleid="circle1"cx="20 "cy="20 "r="10 ’’
style="stroke: none; fill: #ff0000;"/>
</svg>
<script>
$(”#target").mousemove(function (event)
{
var circle = $("#circlel");
circle.attr("cx", event.clientX);
circle.attr("cy", event.clientY);
});
</script>
</body>
SVG grouped with shapes
<svg x="100"
<g transform="rotate(45 50 50)">
<line x1="10" y1="10" x2="85" y2="10"
Style="stroke: #006600;"/>
<rect x="10“ y="20" height="50" width="75"
style="stroke: #006600; fill: #006600"/>
<text x="10" y="90" style="stroke: #660000; fill: #660000">
Text grouped with shapes</text>
</g>
</svg>
Rectangle with a rotate
<svg xmlns="HTTP: //www.w3.org/2000/svg"
xmlns: xlink="HTTP: //www.w3.org/1999/xlink">
<rect x="50” y="50" height="110" width="110"
style="stroke: #ff0000; fill: #ccccff"
transform="translate (3 0) rotate(45 50 50)"
>
</rect>
<text x="70" y="100"
transform="translate(30) rotate(45 50 50)"
>Hello World</text>
</svg>
Transform and translate
<rect x="20" y="20" width="50" height="50"
style="fill: #cc3333"/>
<rect x="20" y="20" width="50" height="50"
style="fill: #3333cc"
transform=”translate(75, 25)” />
Rotate
<rect x="20" y="20" width="40" height="40"
style="stroke: #3333cc; fill: none;"
/>
<rect x="20" y="20" width="40" height="40"
style="fill: #3333cc"
transform="rotate(15)"
/>
Scale ups and downs a size
<rect x="10" y="10" width="20" height="30"
style="stroke: #3333cc; fill: none;" />
<rect x="10" y="10" width="20" height="30"
style="stroke: #000000; fill: none;"
transform="scale(2)" />
SVG path element
The <path> element is used to define a path.
The following commands are available for path data:
- M = moveto
- L = lineto
- H = horizontal lineto
- V = vertical lineto
- C = curveto
- S = smooth curveto
- Q = quadratic Byyzier curve
- T = smooth quadratic Byyzier curveto
- A = elliptical Arc
- Z = closepath
Define a path that starts at position 150, 0 with a line to position 75, 200 then from there, a line to 225, 200 and finally closing the path back to 150, 0:
<svg xmlns="HTTP: //www.w3.org/2000/svg" version="1.1">
<path d="M150 0 L75 200 L225 200 Z" />
</svg>
Question 16.
What are selectors in CSS?
Answer:
Selectors help to select an element to which you want to apply a style. For example, below is a simple style called as ‘. intro” which applies red color to background of a HTML element.
<style>
.intro
{
background-color: red;
}
</style>
To apply the above “intro” style to div we can use the “class” selector as shown in the code.
<div class="intro">
<p>My name is Shivprasad koirala.</p>
<p>I write interview questions.</p>
</div>
Question 17.
How can you apply CSS style using ID value?
Answer:
So let’s say you have an HTML paragraph tag with id “text” as shown in the below snippet.
<p id=”mytext”>This is HTML interview questions.</p>
You can create a style using ” #” selector with the ” id” name and apply the CSS value to the paragraph tag. So to apply style to “mytext” element we can use “#mytext” as shown in the CSS code.
<style>
#mytext
{
background-color: yellow;
}
</style>
Quick revision of some important selectors.
Set all paragraph tags background color to yellow.
P, h1
{
background-color: yellow;
}
Sets all paragraph tags inside div tag to yellow background.
div p
{
background-color: yellow;
}
Sets all paragraph tags following div tags to yellow background.
div+p
{
background-color: yellow;
}
Sets all attribute with “target” to yellow background.
a[target]
{
background-color: yellow;
}
<a href="HTTP: //www.questpond.com">ASP.NET interview questions</a>
<a href="HTTP:- //www.questpond.com" target="_blank">c# interview questions</ a>
<a href="HTTP: //www.questpond.org" target="_top">.NET interview questions with answers</a>
Set all elements to yellow background when control gets focus.
input: focus
{
background-color: yellow;
}
Set hyperlinks according to action on links.
a: link (color: green;}
a: visited (color: green;}
a: hover (color: red;}
a: active (color: yellow;}
Most Important HTML 5 and CSS 3 Interview Questions in .Net
Question 18.
What is the use of column layout in CSS?
Answer:
CSS column layout helps you to divide your text into columns. For example, consider the below magazine news which is one big text but we need to divide the same into 3 columns with a border in-between as shown in Figure 9.14. That’s where HTML 5 columns layout comes to help
IMG
To implement column layout we need to specify the following:
- How many columns do we want to divide the text into?
To specify the number of columns, we need to us,e column count. “Webkit” and “Moz-column” are needed for Chrome and Firefox, respectively.
-moz-column-count: 3; /* Firefox */
-Webkit-column-count: 3; /* Safari and Chrome */
column-count: 3;
- How much gap do we want to give between those columns?
-moz-column-gap: 40px; /* Firefox */
-Webkit-column-gap: 40px; /* Safari and Chrome */
column-gap”: 20px;
- Do you want to draw a line between those columns, if yes how much thick?
-moz-column-rule: 4px outset #ff00ff; /* Firefox */
-Webkit-column-rule: 4px outset #ff00ff; /* Safari and Chrome */
column-rule: 6px outset ttffOOff;
Below is the complete code for the same.
<style>
.magazine
{
-moz-column-count: 3; /* Firefox */ _
-Webkit-column-count: 3; /* Safari and Chrome */
column-count: 3;
-moz-column-gap: 40px; /* Firefox */
-Webkit-column-gap: 40px; /* Safari and Chrome */
column-gap: 20px;
-moz-column-rule: 4px outset ttffOOff; /* Firefox */
-Webkit-column-rule: 4px outset #ff00ff; /* Safari and Chrome'*/
column-rule: 6px outset #ff00ff;
}
</style>
You can then apply the style to the text by using the class attribute.
<div class="magazine">
Your text goes here which you want to divide into 3 columns.
</div>
Question 19.
Can you explain the CSS box model?
Answer:
The CSS box model is a rectangular space around an HTML element that defines the border, padding, and margin as shown in Figure 9.15.
Border: This defines the maximum area in which the element will be contained. We can make the border visible, invisible, define height and width, etc.
Padding: This defines the spacing between border and element.
So for example, if we want to send data below is the ASP.NET code for the same. Please note the content type is set to text/event.
Response.ContentType="text/event-stream";
Response.Expires=-1;
Response.Write("data: " + DateTime.Now.ToString( ));
Response .'Flush ( ) ;
To retry after 10 seconds below is the command.
Response. Write(“retry: 10000’);
1 If you want to attach an event we need to use the “addEventListener” event as shown in the below code.
source.addEventListener('message', function(e)
{
console.log(e.data);
: }, false);
From the server side the below message will trigger the “message” function of JavaScript.
event: message
data: hello
Question 20.
What is the local storage concept in HTML 5?
Answer:
Many times we would like to store information about the user locally on the computer. For example, let’s say the user has half-filled a long-form and suddenly the Internet connection breaks off. So the user would like you to store this information locally and when the Internet comes back. He/she would like to get that information and send it to the server for storage.
Modern browsers have storage called “Local storage” in which you can store this information.
Question 21.
How can we add and remove data from local storage?
Answer:
Data is added to local storage using “key” and “value”. Below sample code shows country data “India” added with key value “Key00l”.
localStorage.setltem(“Key001”, “India’);
To retrieve data from local storage we need to use “get item” providing the key name.
var country = localStorage.getltem(“Key001’);
You can also store JavaScript object’s in the local storage using the below code.
var country = { };
country.name = "India";
country.code = "I001";
localStorage.setltem("I001", country);
var countryl = localStorage.getitem("I001");
If you want to store in JSON format you can use “JSON. stringify” function as shown in the below code.
localStorage.setltem(“l001”, JSON.stringify(country));
Question 22.
What is the lifetime of local storage?
Answer:
Local storage does not have a lifetime it will stay until either the user clear it from the browser or you remove it using JavaScript code.
Question 23.
What is the difference between local storage and cookies?
Answer:
|
Cookies |
Local storage |
| Client-side / Server side |
Data accessible both at client, side and server-side. Cookie data is sent to the server-side with every request. |
Data is accessible only at the local browser-side. Server cannot access local storage until deliberately sent to the server via POST or GET. |
| Size |
4095 bytes per cookie. |
5 MB per domain. |
| Expiration |
Cookies have expiration attached to it. So after that expiration the cookie and the cookie data get’s deleted. |
There is no expiration data. Either the end user needs to delete it from the browser or programmatically using JavaScript we need to remove the same. |
Question 24.
What is session storage and how can you create one?
Answer:
Session storage is the same like local storage but the data is valid for a session. In simple words, the data is deleted as soon as you close the browser.
To create session storage you need to use “sessionStorage.variablename”. In the below code we have created a variable called “click count”.
If you refresh the browser the count increases. But if you close the browser and start again the “clickcount” variable starts from zero.
if(sessionStorage.clickcount)
{
sessionStorage. clickcount-Number (sessionStorage .‘clickcount) +1 ;
}
else
{
sessionStorage.clickcount = 0;
}
Question 25.
What is the difference between session storage and local storage?
Answer:
Local storage data persists forever but session storage is valid until the browser is open, as soon as the browser closes the session variable resets.
Question 26.
What is WebSQL?
Answer:
WebSQL is a structured relational database at the client browser side. It’s a local RDBMS (Relational Database Management System) inside the browser on which you can fire SQL (Structured Query Language) queries.
Question 27.
Is WebSQL a part of HTML 5 specification?
Answer:
No, many people label it as HTML 5 but it is not part of the HTML 5 specification. The specification is based around SQLite.
Question 28.
So how can we use WebSQL?
Answer:
The first step we need to do is open the database by using the “open database” function as shown below. The first argument is the name of the database, the next is the version, then a simple textual title, and finally the size of the database.
var db=openDatabase(‘dbCustomer’, ‘1.0’, ‘Customer app’, 2 * 1024 * 1024);
To execute SQL we then need to use the “transaction” function and call the “execute SQL” function to fire SQL.
db.transaction(function (tx)
{
tx.executeSql('CREATE TABLE IF NOT EXISTS tblCust(id unique, customername)');
tx.executeSql('INSERT INTO tblcust (id, customername) VALUES(1, "shiv")');
tx.executeSql('INSERT INTO tblcust (id, customername) VALUES (2, "raju")');
}
In case you are firing “SELECT” query you will get data is “results” collection which we can loop (using loop) and display in the HTML Ul (User Interface).
db.transaction(function (tx)
{
tx.executeSql(’SELECT * FROM tblcust', [], function (tx, results)
{
for (i = 0; i <results.rows.length; i++)
{
msg = ”<p><b>" + results . rows . item(i). customerName + " </bx/p>" ;
document.querySelector('#customer).innerHTML += msg;
}
}, null);
}) ;
Question 29.
What is application cache in HTML5?
Answer:
One of the most demanded things by end-user is offline browsing. In other words, if an internet connection is not available page should come from browser cache, i.e., offline and application cache helps you to achieve the same. Application cache helps you to specify which files should be cached and not cached.
Question 30.
So how do we implement application cache in HTML 5?
Answer:
The first thing in we need to specify is the “MANIFEST” file, “MANIFEST” file helps you to define how your caching should work. Below is the structure of the manifest file:
CACHE MANIFEST
# version 1.0
CACHE:
Login.aspx
- All manifest file starts with CACHE MANIFEST statement.
- #( hash tag) helps to provide the version of the cache file.
- CACHE command specifies which files need to be cached.
- The content type of the manifest file should be “text/cache-manifest”.
Below is how to cache manifest has been provided using ASP.NET C#.
Response.ContentType = "text/cache-manifest";
Response.Write("CACHE MANIFEST \n");
Response.Write("# 2012-02-21 v1.0.0 \n");
Response.Write("CACHE: \n");
Response.Write("Login.aspx \n");
Response.Flush( );
Response.End( );
One the cache manifest file is created the next thing is to provide the link of the manifest file in the HTML page as shown below. ]
<html manifest= "cache. aspx">
When the above file runs the first time it gets added to the browser application cache and in case the server goes down the page is served from the application cache.
Question 31.
So how do we refresh the application cache of the browser?
Answer:
Application cache is removed by changing the version number to a new version number as specified in ‘ the ” #” tag in the below code.
CACHE MANIFEST
# version 2.0(new)
CACHE:
Login.aspx
Aboutus. aspx
NETWORK:
Pages.aspx
Question 32.
What is the fallback in the Application Cache?
Answer:
Fallback in the application cache helps you to specify the file which will be displayed if the server is not v reachable. For instance, in the below manifest file we are saying if someone hits “/home” and if the server is not reachable then “homeoffline.html” file should be served. v
FALLBACK:
/home/ /homeoffline.html
Question 33.
What is a network in Application Cache?
Answer:
Network command says files which should not be cached. For example, in the below code we are s saying that “home.aspx” should never be cached and or available offline.
NETWORK:
home.aspx