Python Data Persistence – Table with Compound Partition Key
Iball pythons: In the above example, the products table had been defined to have a partition key with a single primary key. Rows in such a table are stored in different nodes depending upon the hash value of the primary key. However, data is stored across the cluster using a slightly different method when the table has a compound primary key. The following table’s primary key comprises two columns.
cq1sh:mykeyspace> create table products . . . ( . . . productID int, . . . manufacturer text, . . . name text, . . . price int, . . . primary key(manufacturer, productID) . . . ) ;
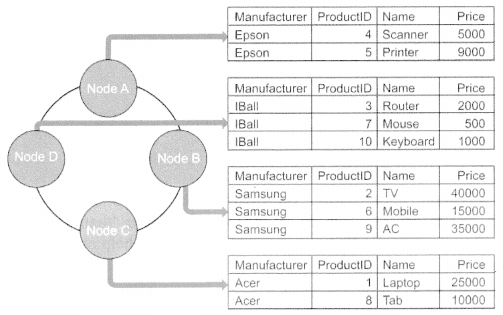
For this table, ‘manufacturer’ is the partition key and ‘productID’ behaves as a cluster key. As a result products with similar ‘manufacturer’ are stored in the same node. Let us understand with the help of the following example. The table contains the following data.
- Python Data Persistence – Create Keyspace
- Data Persistence – Python – PyMongo
- Python Data Persistence – ORM – Querying
Example
cq1sh:mykeyspace> select * from products; productid | manufacturer | name | price ---------------+-----------------+----------------+----------- 5 | 'Epson' | 'Printer' | 9000 10 | 'IBall' | 'Keyboard' | 1000 1 | 'Acer' | 'Laptop' | 25000 8 | 'Acer' | 'Tab' | 10000 2 | 'Samsung' | 'TV' | 40000 4 | 'Epson' | 'Scanner' | 5000 7 | 'IBall' | 'Mouse' | 500 6 | 'Samsung' | 'Mobile' | 15000 9 | 'Samsung' | 'AC' | 35000 3 | ’IBall' | 'Router' | 2000 (10 rows)
Rows in the above table will be stored among nodes such that products from the same manufacturer are together, (figure 12.5)