
Python Data Persistence – Python – Cassandra
In this last chapter, we are going to deal with another important NOSQL database – Cassandra. Today some of the biggest IT giants (including FaceBook, Twitter, Cisco, and so on) use Cassandra because of its high scalability, consistency, and fault-tolerance. Cassandra is a distributed database from Apache Software Foundation. It is a wide column store database. A large amount of data is stored across many commodity servers which makes data highly available.
Cassandra Architecture
The fundamental unit of data storage is a node. A node is a single server in which data is stored in the form of the keyspace. For understanding, you can think of keyspace as a single database. Just as any server running a SQL engine can host multiple databases, a node can have many key spaces. Again, like in a SQL database, keyspace may have multiple column families which are similar to tables.
However, the architecture of Cassandra is logically as well as physically different from any SQL-oriented server (Oracle, MySQL, PostgreSQL, and so on). Cassandra is designed to be a foolproof database without a single point of failure. Hence, data in one node is replicated across a peer-to-peer network of nodes. The network is called a data center, and if required, multiple data centers are interconnected to form a cluster. Replication strategy and replication factor can be defined at the time of the creation of a keyspace. (figure 12.1) ‘
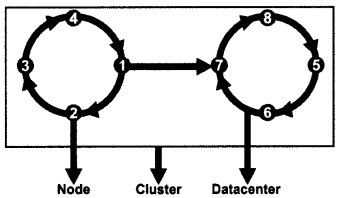
Each ‘write’ operation over a keyspace is stored in Commit Log, which acts as a crash-recovery system. After recording here, data is stored in a Mem-table. Mem-table is just a cache or buffer in the memory. Data from the mem-table is periodically flushed in SSTables, which are physical disk files on the node.
- Data Persistence – Python – PyMongo
- Python Data Persistence – RDBMS Concepts
- Python Data Persistence – Create Keyspace
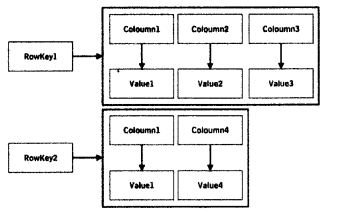
Cassandra’s data model too is entirely different from a typical relational database. It is often, described as a column store or column-oriented NOSQL database. A keyspace holds one or more column families, similar to the table in RDBMS. Each table (column family) is a collection of rows, each of which stores columns in an ordered manner. Column, therefore, is the basic unit of data in Cassandra. Each column is characterized by its name, value, and timestamp.
The difference between a SQL table and Cassandra’s table is that the latter is schema-free. You don’t need to define your column structure ahead of time. As a result, each row in a Cassandra table may have columns with different names and variable numbers.
Installation
The latest version of Cassandra is available for download athttp://cassandra. apache.org/download/. Community distributions of Cassandra (DDC) can be found at https://academy.datastax.com/planet-cassandra/cassandra. Code examples in this chapter are tested on DataStax distribution installed on Windows OS.
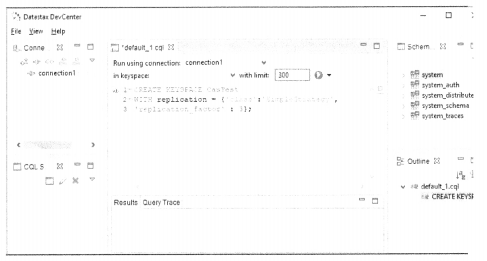
Just as any relational database uses SQL for performing operations on data in tables, Cassandra has its own query language CQL which stands for Cassandra Query Language. The DataStax distribution comes with a useful front-end IDE for CQL. All operations such as creating keyspace and table, running different queries, and so on can be done both visually as well as using text queries. The following diagram shows a view of DataStax DevCenter IDE.(figure 12.3)
CQL Shell
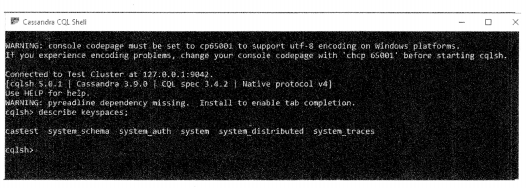
Cassandra installation also provides a shell inside which you can execute CQL queries. It is similar to> MySQL console, SQLite console, or Oracle’s SQL Plus terminal. (figure 12.4)
We shall first learn to perform basic CRUD operations with Cassandra from inside CQLSH and then use Python API for the purpose.
Inserting Rows
INSERT statement in CQL is exactly similar to one in SQL. However, the column list before the ‘VALUES’ clause is not optional as is the case in SQL. That is because, in Cassandra, the table may have a variable number of columns.
cq1sh:mykeyspace> insert into products (productID, name, price) values (1, 1 Laptop 1,25000);
Issue INSERT statement multiple numbers of times to populate ‘products’ table with sample data given in chapter 9. You can also import data from a CSV file using the copy command, as follows:
cq1sh:mykeyspace> copy products (productID, name, price) . . . from ’pricelist.csv’ with the delimiter,’ and header=true;