
We have compiled most frequently asked SQL Server Interview Questions which will help you with different expertise levels.
SQL Server Interview Questions on Database Concepts
Question 1.
What is database or database management systems (DBMS)?
Answer:
Twist: – What’s the difference between file and database? Can files qualify as a database?
Note Probably these questions are too basic for experienced SQL SEP VER guys. But
from freshers' point of view, it can be a difference between getting a job and being jobless.
The database provides a systematic and organized way of storing, managing, and retrieving from the collection of logically related information.
Secondly, the information has to be persistent, which means even after the application is closed the information should be persisted.
Finally, it should provide an independent way of accessing data and should not be dependent on the application to access the information.
Ok, let me spend a few sentences more on explaining the third aspect. Below is a simple figure of a text file that has personal detail information. The first column of the information is Name, second address and finally the phone number. This is a simple text file that was designed by a programmer for a specific application.
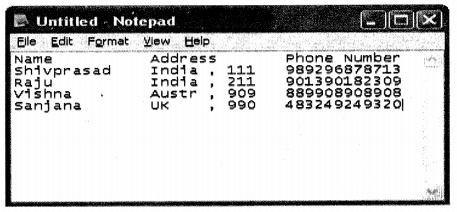
It works fine in the boundary of the application. Now some years down the line a third-party application has to be integrated with this file, so in order for the third-party application to integrate properly it has the following options:-
- Use interface of the original application.
- Understand the complete detail of how the text file is organized, example the first column is Name, then address, and finally phone number. After analyzing write a code that can read the file, parse it, etc ….Hmm lot of work right.
That’s the main difference between a simple file and a database; a database has an independent way (SQL) of accessing information while simple files do not (That answers my twisted question defined above). File meets the storing, managing, and retrieving part of a database but not the independent way of accessing data.
Note Many experienced programmers think that the main difference is that files can
not provide multi-user capabilities which a DBMS provides. But if you look at
some old COBOL and C programs where file were the only means of storing
data, you can see functionalities like locking, multi-user etc provided very efficiently.
So it's a matter of debate if some interviewers think this as a main difference between files and
database accept it... going in to debate is probably loosing a job.
(Just a note for fresher’s multi-user capabilities means that at one moment of time more than one user should be able to add, update, view, and delete data. All DBMS provides this as inbuilt functionalities but if you are storing information in files it’s up to the application to write a logic to achieve these functionalities)
Question 2.
What’s the difference between DBMS and RDBMS?
Answer:
Ok as said before DBMS provides a systematic and organized way of storing, managing, and retrieving from collection of logically related information. RDBMS also provides what DBMS provides but above that it provides relationship integrity. So in short we can say
RDBMS = DBMS + REFERENTIAL INTEGRITY
For example, in figure 1.1 every person should have an address, this is a referential integrity between “Name” and “Address”. If we break this referential integrity in DBMS and File’s it will not complain, but RDBMS will not allow you to save this data if you have defined the relation integrity between person and addresses. These relations are defined by using “Foreign Keys” in any RDBMS.
Many DBMS companies claimed their DBMS product was RDBMS compliant, but according to industry rules and regulations if the DBMS fulfills the twelve CODD rules it’s truly an RDBMS. Almost all DBMS (SQL SERVER, ORACLE, etc) fulfill all the twelve CODD rules and are considered as truly RDBMS.
Note One of the biggest debates, Is Microsoft Access an RDBMS? We will be answering this question in a later section.
Question 3.
(DB) What are CODD rules?
Answer:
Twist: – Does SQL SERVER support all the twelve CODD rules?
Note This question can only be asked on two conditions when the interviewer is expecting you to be at a
DBA job or you are a complete fresher, yes and not to mention the last one he treats CODD rules as a religion.
We will try to answer this question from the perspective of SQL SERVER.
In 1969 Dr. E. F. Codd laid down some 12 rules which a DBMS should adhere to in order to get the logo of a true RDBMS.
Rule 1: Information Rule.
“All information in a relational database is represented explicitly at the logical level and in exactly one way – by values in tables.”
In SQL SERVER all data exists in tables and are accessed only by querying the tables.
Rule 2: Guaranteed Access Rule.
“Each and every datum (atomic value) in a relational database is guaranteed to be logically accessible by resorting to a combination of the table name, primary key value, and column name.”
In flat files, we have to parse and know the exact location of field values. But if a DBMS is true, RDBMS you can access the value by specifying the table name, field name, for instance, Customers. Fields [‘Customer Name’]
SQL SERVER also satisfies this rule in ADO.NET we can access field information using table names and field names.
Rule 3: Systematic treatment of null values.
“Null values (distinct from the empty character string or a string of blank characters and distinct from zero or any other number) are supported in fully relational DBMS for representing missing information and inapplicable information in a systematic way, independent of data type.”
In SQL SERVER if there is no data existing NULL values are assigned to it. Note NULL values in SQL SERVER do not represent spaces, blanks, or a zero value; it’s a distinct representation of missing information and thus satisfying rule 3 of CODD.
Rule 4: Dynamic online catalog based on the relational model.
“The database description is represented at the logical level in the same way as ordinary data, so that authorized users can apply the same relational language to its interrogation as they apply to the regular data.”
The Data Dictionary is held within the RDBMS, thus there is no need for off-line volumes to tell you the structure of the database.
Rule 5: Comprehensive data sub-language Rule.
“A relational system may support several languages and various modes of terminal use (for example, the fill-in-the-blanks mode). However, there must be at least one language whose statements are expressible, per some well-defined syntax, as character strings and that is comprehensive in supporting all the following items
- Data Definition
- View Definition
- Data Manipulation (Interactive and by program).
- Integrity Constraints
- Authorization.
- Transaction boundaries (Begin, commit and rollback)
SQL SERVER uses SQL to query and manipulate data that has well-defined syntax and is being accepted as an international standard for RDBMS.
Note According to this rule CODD has only mentioned that some language should be present to support it,
but not necessary that it should be SQL. Before 80's different database vendors where providing there own flavor of
syntaxes until in 80 ANSI- SQL came into standardize this variation between vendors. As ANSI-SQL is quiet limited,
every vendor including Microsoft introduced there additional SQL syntaxes in addition to the support of ANSI-SQL.
You can see SQL syntaxes varying from vendor to vendor.
Rule 6: View updating Rule
“All views that are theoretically updatable are also updatable by the system.”
In SQL SERVER not only views can be updated by the user, but also by SQL SERVER itself.
Rule 7: High-level insert, update and delete.
“The capability of handling a base relation or a derived relation as a single operand applies not only to the retrieval of data but also to the insertion, update, and deletion of data.”
SQL SERVER allows you to update views which in turn affect the base tables.
Rule 8: Physical data independence.
“Application programs and terminal activities remain logically unimpaired whenever any changes are made in either storage representations or access methods.”
Any application program (C#, VB.NET, VB6 VC++, etc) Does not need to be aware of where the SQL SERVER is physically stored or
what type of protocol it’s using, database connection string encapsulates everything.
Rule 9: Logical data independence.
“Application programs and terminal activities remain logically unimpaired when information-preserving changes of any kind that theoretically permit un-impairment are made to the base tables.”
Application programs written in C# or VB.NET do not need to know about any structural changes in SQL SERVER database example: – adding of new field etc.
Rule 10: Integrity Independence.
“Integrity constraints specific to a particular relational database must be definable in the relational data sub-language and storable in the catalog, not in the application programs.”
In SQL SERVER you can specify data types (integer, varchar, Boolean, etc) which put in data type checks in SQL SERVER rather than through application programs.
Rule 11: Distribution independence
“A relational DBMS has distribution independence.”.
SQL SERVER can spread across more than one physical computer and across several networks; but from an application program point of view, it is not a big difference but just specifying the SQL SERVER name and the computer on which it is located.
Rule 12: Non-subversion Rule.
“If a relational system has a low-level (single-record-at-a-time) language, that low level cannot be used to subvert or bypass the integrity Rules and constraints expressed in the higher-level relational language (multiple-records-at-a-time).”
In SQL SERVER whatever integrity rules are applied on every record are also applicable when you process a group of records using an application program in any other language (example: – C#, VB.NET, J#, etc…).
Readers can see from the above explanation SQL SERVER satisfies all the CODD rules, some database gurus consider SQL SERVER as not truly RDBMS, but that’s a matter of debate.
Question 4.
Is the access database an RDBMS?
Answer:
Access fulfills all rules of CODD, so from this point of view yes it’s truly RDBMS. But many people can contradict it as a large community of Microsoft professionals thinks that ACCESS is not.
Question 5.
What’s the main difference between ACCESS and SQL SERVER?
Answer:
As said before access fulfills all the CODD rules and behaves as a true RDBMS. But there’s a huge difference from an architecture perspective, due to which many developers prefer to use SQL SERVER as a major database rather than access. Following is the list of architecture differences between them:-
- Access uses file server design and SQL SERVER uses the Client / Server model. This forms the major difference between SQL SERVER and ACCESS.
Note Just to clarify what is client-server and file server I will make a quick description of widely accepted
architectures. There are three types of architecture:-
- mainframe architecture (This is not related to the above explanation but just mentioned it as it can be useful during the interview and also for comparing with other architecture)
- File sharing architecture (Followed by ACCESS)
- Client-Server architecture (Followed by SQL SERVER)
In Main Frame architecture all the processing happens on the central host server. The user interacts through dump terminals which only send keystrokes and information to the host. All the main processing happens on the central host server. So the advantage of such type of architecture is that you need the least configuration clients. But the disadvantage is that you need a robust central host server like Main Frames.
In File sharing architecture which is followed by an access database, all the data is sent to the client terminal and then processed. For instance, you want to see customers who stay in INDIA, in File Sharing architecture all customer records will be sent to the client PC regardless of whether the customer belongs to INDIA or not. On the client PC customer records from India are sorted/filtered out and displayed, in short, all processing logic happens on the client PC.
So in this architecture, the client PC should have a heavy configuration and also it increases network traffic as a lot of data is sent to the client PC. But the advantage of this architecture is that your server can be of low configurations.
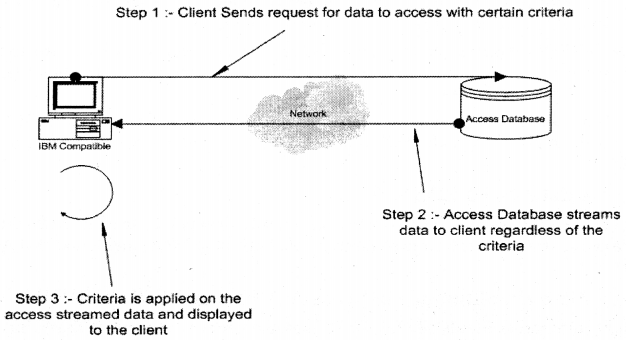
In a client-server architecture, the above limitation of the file server architecture is removed. In a client-server architecture, you have two entities client and the database server. The file server is now replaced by the database server. Database server takes up a load of processing any database-related activity and the client any validation aspect of the database. As the work is distributed between the entities it increases scalability and reliability. Second, the network traffic also comes down as compared to the file server.
For example, if you are requesting customers from INDIA, the database server will sort/ filter and send only INDIAN customer details to the client, thus bringing down the network traffic tremendously. SQL SERVER follows the client-server architecture.
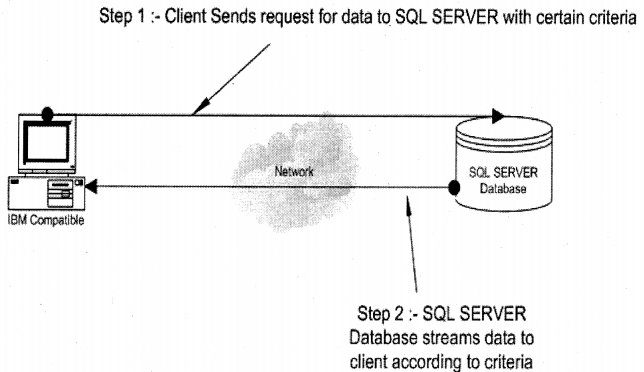
- The second issue comes in terms of reliability. In Access the client directly interacts with the access file, in case there is some problem in the middle of the transaction there are chances that access file can get corrupt. But in SQL SERVER the engine sits in between the client and the database, so in case of any problems in the middle of the transaction, it can revert back to its original state.
Note SQL SERVER maintains a transaction log by which you can revert back to your original state in case of any crash.
When your application has to cater to huge load demand, highly transactional environment, and high concurrency then it’s better to go for SQL SERVER or MSDE.
- But when it comes to cost and support then access stands better than SQL SERVER. In the case of SQL SERVER, you have to pay per client license, but access runtime is free.
Summarizing SQL SERVER gains points in terms of network traffic, reliability and. scalability vice-versa access gains
points in terms of the cost factor.
Question 6.
What’s the difference between MSDE and SQL SERVER 2000?
Answer:
MSDE is a royalty-free, redistributable, and cut short version of the giant SQL SERVER database. It’s primarily provided as a low-cost option for developers who need a database server that can easily be shipped and installed. It can serve as a good alternative for the Microsoft Access database as it overcomes quite a lot of problems that ACCESS has.
Below is a complete list that can give you a good idea of the differences:-
1. Size of database: – MS ACCESS and MSDE have a limitation of 2GB while SQL SERVER has 1,048,516 TB1,
2. Performance degrades in MSDE 2000 when a maximum number of concurrent operations goes above 8 or equal to 8. It does not mean that you can not have more than eight concurrent operations but the performance degrades. Eight connection performance degradation is implemented by using SQL SERVER 2000 workload governor (we will be looking into more detail of how it works). As compared to SQL SERVER 2000 you can have 32,767 concurrent connections.
3. MSDE does not provide OLAP and Data warehousing capabilities.
4. MSDE does not have a support facility for SQL mail.
5. MSDE 2000 does not have GUI administrative tools such as enterprise manager, Query analyzer, or Profiler, But there are roundabout ways by which you can manage MSDE 2000′
6. Old command-line utility OSQL.EXE,
7.VS.NET IDE Server Explorer: – Inside VS.NET IDE you have a functionality that can give you a nice GUI administrative tool to manage IDE,
8. SQL SERVER WEB Data administrator installs a web-based GUI which you can use to manage your database. For any details refer http;//www.microsoft.com/ downloads/details, aspx?familyid=c039a798-c57a-419e-acbc~2a332cb7f959& displaylang-en
9. SQL-DMO objects can be used to build your custom UI.
10. There are lots of third-party tools which provide administrative capability GUI, which is out of the scope of the book as it’s only meant for interview questions.
11. MSDE does not support Full-text search,
Summarizing There are two major differences first is the size limitation (2 GB) of the database and
the second are the concurrent connections (eight concurrent connections) which are limited by using
the workload governor. During the interview, this answer will suffice if he is really testing your knowledge.
Question 7.
What is SQL SERVER Express 2005 Edition?
Answer:
Twist: – What’s the difference between SQL SERVER Express 2005and MSDE 2000?
Note Normally comparison is when the product is migrating from one version to another version.
When SQL SERVER 7,0 is migrating to SQL 2000, asking differences was one of the favorite questions,
SQL SERVER Express edition is a scaled-down version of SQL SERVER 2005 and the next evolution of MSDE.
Below listed are some major differences between them:-
1. MSDE’s maximum database size is 2GB while SQL SERVER Express has around 4GB.
2. In terms of programming language support MSDE has only TSQL, but SQL SERVER Express has TSQL and. NET. In SQL SERVER Express 2005 you can write your stored procedures using. NET.
3. SQL SERVER Express does not have connection limitation which MSDE had and was controlled through the workload governor.
4. There was no XCOPY support for MSDE, SQL SERVER Express has it.
5. DTS is not present in SQL SERVER express while MSDE has it.
6. SQL SERVER Express has reporting services while MSDE does not.
7. SQL SERVER Express has native XML support and MSDE does not.
Note: Native XML support mean now in SQL SERVER 2005
8. You can create a field with the data type “XML”.
9. You can provide SCHEMA to the SQL SERVER fields with the “XML” data type.
10. You can use new XML manipulation techniques like “XQUERY” also called “XML QUERY”.
There is a complete chapter on SQL SERVER XML Support so till then this will suffice.
Summarizing the major difference is database size (2 GB and 4 GB), support of .NET support in stored procedures,
and native support for XML. This is much can convince the interviewer that you are clear about the
differences.
Question 8.
(DB) What is SQL Server 2000 Workload Governor?
Answer:
Workload governor limits the performance of SQL SERVER Desktop Engine (MSDE) if the SQL engine receives more load than what is meant for MSDE. MSDE was always meant for trial purposes and non-critical projects. Microsoft always wanted companies to buy their full-blown version of SQL SERVER so in order that they can put limitations on MSDE performance and the number of connections they introduced Workload governor.
Workload governor sits between the client and the database engine and counts a number of connections per database instance. If the Workload governor finds that the number of connections exceeds eight connections, it starts stalling the connections and slowing down the database engine.
Note It does not limit the number of connections but makes the connection request go slow.
By default, 32,767 connections are allowed both for SQL SERVER and MSDE. But it just makes
the database engine go slow above eight connections.
Question 9.
What’s the difference between SQL SERVER 2000 and 2005?
Answer:
Twist: – What’s the difference between Yukon and SQL SERVER 2000?
Note This question will be one of the favorites during SQL SERVER Interviews. I have marked the points
which should be said by developers as PG and DBA for Database Administrator.
Following are some major differences between the two versions:-
1. (PG) The most significant change is the .NET integration with SQL SERVER 2005. Stored procedures, User-defined functions, triggers, aggregates, and user-defined types can now be written using your own favorite .NET language (VB.NET, C#, J#, etc .). This support was not there in SQL SERVER 2000 where the only language was T-SQL. In SQL 2005 you have support for two languages T-SQL and. NET.
2. (PG) SQL SERVER 2005 has reporting services for reports which is a newly added feature and do not exist for SQL SERVER 2000.lt was a separate installation for SQL Server 2000.
3. (PG) SQL SERVER 2005 has introduced two new data types varbinary (max) and XML. If you remember in SQL SERVER 2000 we had image and text data types. The problem with image and text data types is that they assign the same amount of storage irrespective of what the actual data size is. This problem is solved using varbinary (max) which acts depending on the amount of data. One more new data type is included “XML” which enables you to store XML documents and also does schema verification. In SQL SERVER 2000 developers used varchar or text data type and all validation had to be done programmatically.
4. (PG) SQL SERVER 2005 can now process direct incoming HTTP requests without an IIS web server. Also stored procedure invocation is enabled using the SOAP protocol.
5. (PG) Asynchronous mechanism is introduced using server events. In the Server event model the server posts an event to the SQL Broker service, later the client can come and retrieve the status by querying the broker.
6. For huge databases SQLSERVER has provided a cool feature called “Data . partitioning”. In data partitioning, you break a single database object such as a table or an index into multiple pieces. But for the client application accessing the single database object “partitioning” is transparent.
7. In SQL SERVER 2000 if you rebuilt clustered indexes even the non-clustered indexes were rebuilt. But in SQL SERVER 2005 building the clustered indexes does not build the non-clustered indexes.
8. Bulk data uploading in SQL SERVER 2000 was done using BCP (Bulk copy program’s) format files. But now in SQL SERVER 2005 bulk data uploading uses XML file format.
9. In SQL SERVER 2000 there was a maximum of 16 instances, but in 2005 you can have up to 50 instances.
10. SQL SERVER 2005 has the support of “Multiple Active Result Sets” also called “MARS”. In previous versions of SQL SERVER 2000 in one connection, you can only have one result set. But now in one SQL connection, you can query and have multiple results set.
11. In previous versions of SQL SERVER 2000, the system catalog was stored in the master database. In SQL SERVER 2005 it’s stored in a resource database which is stored as a sys object, you can not access the sys object directly as in the older version we were accessing the master database.
12. This is one of the hardware benefits which SQL SERVER 2005 has over SQL SERVER 2000 – support of hyperthreading. WINDOWS 2003 supports hyperthreading; SQL SERVER 2005 can take the advantage of the feature unlike SQL SERVER 2000 which did not support hyperthreading.
Note Hyper threading is a technology developed by INTEL that creates two logical processors on a single
physical hardware processor.
13. SMO will be used for SQL Server Management.
14. AMO (Analysis Management Objects) to manage Analysis Services servers, data sources, cubes, dimensions, measures, and data mining models. You can map AMO in the old SQL SERVER with DSO (Decision Support Objects).
15. Replication is now managed by RMO (Replication Management Objects).
Note SMO, AMO and RMO are all using.NETFramework.
16. SQL SERVER 2005 uses the current user execution context to check rights rather than ownership link chain, which was done in SQL SERVER 2000.
Note There is a question on this later see for execution context questions.
17. In previous versions of SQL SERVER the schema and the user name were the same, but in current, the schema is separated from the user. Now the user owns schema.
Note There are questions on this, refer - "Schema" later.
Note Ok below are some Gill changes.
18. Query analyzer is now replaced by query editor.
19. Business Intelligence development studio will be used to create Business intelligence solutions.
20. OSQL and ISQL command-line utility are replaced by SQLCMD utility.
21. SQL SERVER Enterprise manager is now replaced by SQL SERVER Management studio.
22. SERVER Manager which was running in the system tray is now replaced by SQL Computer manager.
23. Database mirror concept supported in SQL SERVER 2005 which was not present in SQL SERVER 2000.
24. In SQL SERVER 2005 Indexes can be rebuilt online when the database is in actual production. If you look back in SQL SERVER 2000 you can not do insert, update and delete operations when you are building indexes.
25. (PG) Other than Serializable, Repeatable Read, Read Committed, and Read Uncommitted isolation level there is one more new isolation level “Snapshot Isolation level”.
Note We will see "Snapshot Isolation level" in detail incoming questions.
Summarizing The major significant difference between SQL SER VER 2000 attd SQL SERVER 2005
is in terms of support of .NET Integration, Snap shot isolation level, Native XML support, handling
HTTP request, Web service support and Data partitioning. You do not have to really say all the above
points during interview, a siveet summary and you will rock.
Question 10.
What are E-R diagrams?
Answer:
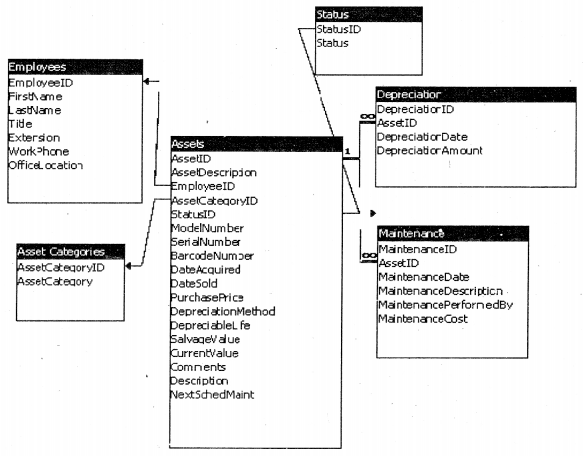
E-R diagram also termed as Entity-Relationship diagram shows relationships between various tables in the database. Example: – Table “Customer” and “CustomerAddresses” have one too many relationships (i.e. one customer can have multiple addresses) this can be shown using the ER diagram. ER diagrams are drawn during the initial stages of the project to forecast how the database structure will shape up. Below is a screenshot of a sample ER diagram of “Asset Management” which ships free with access.
Question 11.
How many types of relationships exist in database designing?
Answer:
There are three major relationship models:-
- One-to-one
As the name suggests you have one record in one table and corresponding to that you have one record in another table. We will take the same sample ER diagram defined for asset management. In the below diagram “Assets” can only have one “Status” at the moment of time (Outdated / Need Maintenance and New Asset). At any moment of time “Asset” can only have one status of the above, so there is a one-to-one relationship between them.
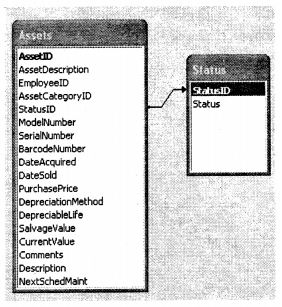
- One-to-many
In this many records in one table corresponds to the one record in another table. Example: – Every customer can have multiple sales. So there exist one-to-many relationships between customer and sales table.
One “Asset” can have multiple “Maintenance”. So “Asset” entity has a one-to-many relationship between them as the ER model shows below.
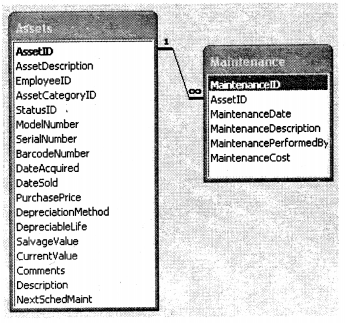
- Many-to-many
In this one record in one table corresponds to many rows in another table and also vice-versa. For instance, In a company one employee can have many skills like java, c#, etc, and also one skill can belong to many employees.
Given below is a sample of many-to-many relationships. One employee can have knowledge of multiple “Technology”. So in order to implement this, we have one more table “EmployeeTechnology” which is linked to the primary key of the “Employee” and “Technology” table.
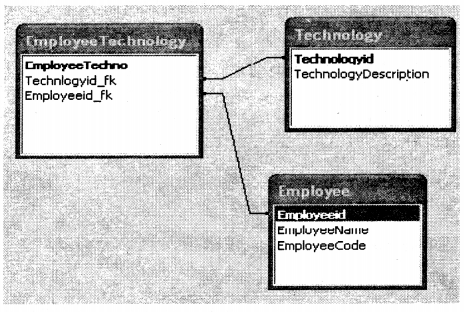
Question 12.
(DB) Can you explain the Fourth Normal Form?
Answer:
Note Whenever interviewer is trying to go above third normal form it can have two reasons ego or to fail yon. Three normal forms are really enough, practically anything more than that is an overdose.
In the fourth normal form, it should not contain two or more independent multi-valued facts about an entity and it should satisfy the “Third Normal form”.
So let’s try to see what multi-valued facts are. If there are two or more many-to-many relationships in one entity and they tend to come to one place is termed as “multi-valued facts”.
| Supplier | Product | Location |
| SK Enterprise | Bottles | Delhi |
| Bell Corporate | Computers | Mumbai |
| Bell Corporate | Computer | Kerala |
| MD Motors | Car | Madras |
In the above table, you can see there are two many-to-many relationships between “Supplier” / “Product” and “Supplier” / “Location” (of in short multi-valued facts). In order for the above example to satisfy fourth normal form, both the many-to-many relationship should go in
different tables.

Question 13.
(DB) Can you explain the Fifth Normal Form?
Answer:
Note UUUHHH if you get his question after joining the company do ask him, did he
himself really use it?
The fifth normal form deals with reconstructing information from smaller pieces of information. These smaller pieces of information can be maintained with less redundancy.
Example: – “Dealers” sells “Product” which can be manufactured by various “Companies”. “Dealers” in order to sell the “Product” should be registered with the “Company”. So these three entities have very much a mutual relationship within them.

The above table shows some sample data. If you observe closely a single record is created using a lot of small information. For instance: – “JM Associate” can sell sweets in the following two conditions:-
- “JM Associate” should be an authorized dealer of “Cadbury”.
- “Sweets” should be manufactured by “Cadbury” company.
These two smaller pieces of information form one record of the above-given table. So in order that the above information to be “Fifth Normal Form” all the smaller information should be in three different places. Below is the complete fifth normal form of the database.
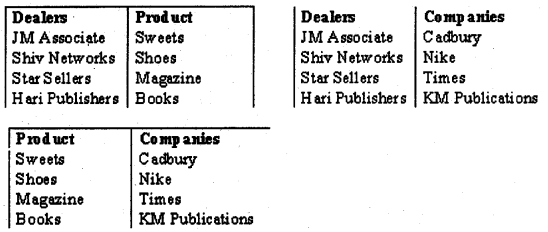
Question 14.
(DB) What’s the difference between the Fourth and Fifth normal forms?
Answer:
Note There is a huge similarity between the Fourth and Fifth normal forms i.e. they address the problem of “Multi-Valuedfacts”.
“Fifth normal form” multi-valued facts are interlinked and “Fourth normal form” values are independent. For instance in the above two questions “Supplier/Product” and “Supplier/Location” are not linked. While in the fifth form the “Dealer/Product/Companies” are completely linked.
Question 15.
(DB) Have you heard about the sixth normal form?
Answer:
Note Arrrrggghhh yes there exists a sixth normal form also. But note guys you can skip this statement or just
in case if you want to impress the interviewer.
If you want a relational system in conjunction with time you use the sixth normal form. At this moment SQL Server does not support it directly. :
Question 16.
What are Extent and Page?
Answer:
Twist: – What’s the relationship between Extent and Page?
Extent is a basic unit of storage to provide space for tables. Every extent has a number of data pages. As new records are inserted new data pages are allocated. There are eight data pages to an extent. So as soon as the eight pages are consumed it allocates a new extent with data pages.
While extent is basic unit storage from a database point of view, the page is a unit of allocation within the extent
Question 17.
(DB)What are the different sections on the Page?
Answer:
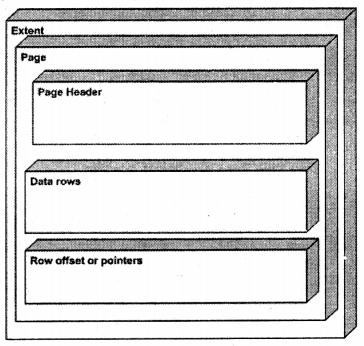
The page has three important sections:-
- Page header
- Actual data i.e. Data row
- Row pointers or Row offset
The page header has information like timestamp, next page number, previous page number, etc. Data rows are where your actual row data is stored. For every data row, there is a row offset which points to that data row.
Question 18.
What are page splits?
Answer:
Pages are contained in extent. Every extent will have around eight data pages. But all eight data pages are not created at once; it’s created depending on data demand. So when a page becomes full it creates a new page, this process is called “Page Split”.
Question 19.
In which files does actually SQL Server store data?
Answer:
Any SQL Server database is associated with two kinds of files: – .MDF and .PDF..MDF files are actual physical database files where your data is stored finally. , LDF (LOG) files are actually data that is recorded from the last time data was committed in the database.
Question 20.
What is Collation in SQL Server?
Answer:
Collation refers to a set of rules that determine how data is sorted and compared. Character data is sorted using rules that define the correct character sequence, with options for specifying case sensitivity, accent marks, kana character types and character width.
Note Different language will have different sort orders.
Case sensitivity
If A and a, B and b, etc. are treated in the same way then it is case-insensitive. A computer treats A and a differently because it uses ASCII code to differentiate the input. The ASCII value of A is 65, while a is 97. The ASCII value of B is 66 and b is 98.
Accent sensitivity
If “a” and “A”, o and “O” are treated in the same way, then it is accent-insensitive. A computer treats “a” and “A” differently because it uses ASCII code for differentiating the input. The ASCII value of “a” is 97 and “A” 225. The ASCII value of V is 111 and “O” is 243.
Kana Sensitivity
When Japanese kana characters Hiragana and Katakana are treated differently, it is called Kana sensitive.
Width sensitivity
When a single-byte character (half-width) and the same character when represented as a double-byte character (full-width) are treated differently then it is width sensitive.
Question 21.
(DB)Can we have a different collation for the database and table?
Answer:
Yes, you can specify different collation sequences for both the entity differently.