
We have compiled most frequently asked .NET Interview Questions which will help you with different expertise levels.
.NET Interview Questions on SQL SERVER
Note: This Chapter is too small to cover SQL Server completely. We suggest you buy our exclusive book SQL Server Interview Question book to gain full confidence during an interview for this product.
Question 1.
What is normalization?
Answer:
Note: A regular .NET programmer working on projects often stumbles in this question, which is but obvious. The bad part is sometimes the interviewer can take this as a very basic question to be answered and it can be a turning point for the interview. So let's cram it.
It is a set of rules that have been established to aid in the design of tables that are meant to be connected through relationships. This set of rules is known as Normalization.
Benefits of normalizing your database will include:
- Avoiding repetitive entries
- Reducing required storage space
- Preventing the need to restructure existing tables to accommodate new data.
- Increased speed and flexibility of queries, sorts, and summaries.
Note: During the interview candidates are expected to answer a maximum of three normal forms.
Following are the three normal forms:
First Normal Form
For a table to be in the first normal form, data must be broken up into the smallest units possible (See Figure 10.1). In addition to breaking data up into the smallest meaningful values, tables in first normal form should not contain repetitions groups of fields.
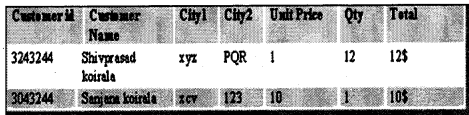
In the example, as shown in Figure 10.1 City1 and City2 are repeating. In order that this table to be in the First normal form, you have to modify the table structure as follows. Also, note that the Customer Name is now broken down to the first name and last name (First normal form data should be broken down to the smallest unit) (See Table 10.2).
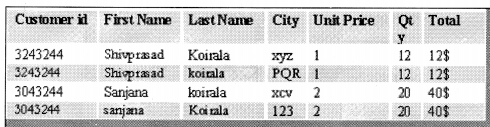
Second Normal form
The second normal form states that each field in a multiple-field primary key table must be directly related to the entire primary key (See Figure 0.3). Or in other words, each non-key field should be a fact about all the fields in the primary key.
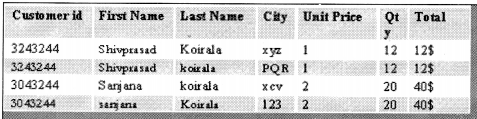
In the above table of customers, City is not linked to any primary field (See Figure 10.4).
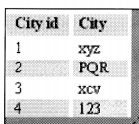
That takes our database to a second normal form.
Third Normal form
A non-key field should not depend on another non-key field. The field “Total” is dependent on “Unit price” and “qty” (See Figure 10.5).

Margin: This defines the spacing between the border and any neighboring elements.
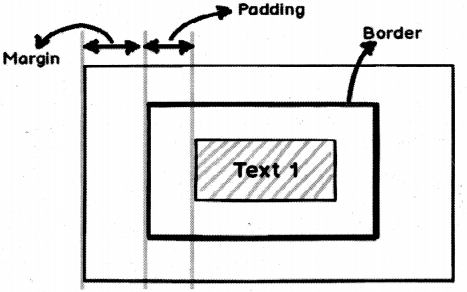
For instance below is a simple CSS code which defines a box with border, padding and margin values.
. box {
width: 200px;
border: 10px solid #9 9c;
padding: 20px;
margin: 50px;
}
Now if we apply the above CSS to a div tag as shown in the below code, your output would be as shown in the Figure 9.16. I have created two test. “Some text” and “Some other text” so that we can see how margin property functions.
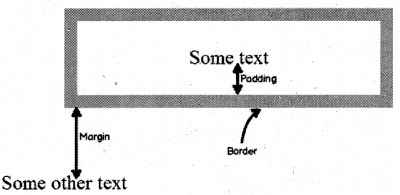
<div align="middle" class="box"> Some text </div> Some other text
Question 2.
Can you explain some text effects in CSS 3?
Answer:
Here the interviewer is expecting you to answer one of two text effects by CSS. Below are two effects that are worth noting.
Shadow text effect
.specialtext
{
text-shadow: 5px 5px 5px #FF0000;
}
Figure 9.17 shows the shadow text effect.
![]()
Word wrap effect
<style>
.breakword
{word-wrap: break-word;}
</style>
Question 3.
What are Web workers and why do we need them?
Answer:
Consider the below heavy for loop code which runs above million times.
function SomeHeavyFunction( )
{
for (i = 0; i < 10000000000000; i++)
{
x = i + x ;
}
}
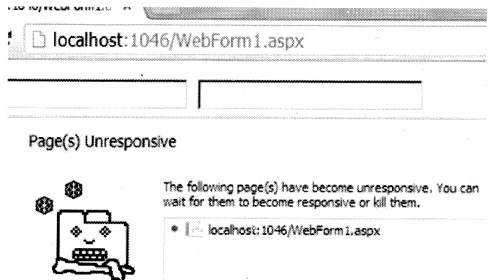
Let’s say the above for loop code is executed on an HTML button click. Now, this method’s execution is synchronous. In other words, the complete browser will wait until the for loop completes.
<input type=”button”onclick=”SomeHeavyFunction();”/>
This can further lead to the browser getting frozen and unresponsive with an error message as shown in Figure 9.19.
So if we can move this heavy for loop in a JavaScript file and run it asynchronously that means the browser does need to wait for the loop then we can have a more responsive browser. That is what the Web workers are for. Web worker helps to execute JavaScript files asynchronously.
Question 4.
What are the restrictions of the Web Worker thread?
Answer:
Web worker threads cannot modify HTML elements, global variables and some window properties like Window. Location. You are free to use JavaScript data types, XMLHTTPRequest calls, etc.
Question 5.
So how do we create a worker thread in JavaScript?
Answer:
To create a worker thread we need to pass the JavaScript file name and create the worker object.
var worker = new Worker(“MyHeavyProcess.js’);
To send a message to the worker object we need to use “PostMessage”, below is the code for the same.
worker.postMessage(“test”);
When the worker thread sends data we get it in the “OnMessage” event on the caller’s end.
worker.onmessage = function (e)
{
document.getElementByld("txt1").value = e.data;
} ;

The heavy loop is in the “MyHeavyProcess.js” JavaScript file, below is the code for the same. When the JavaScript file wants to send message it uses “postMessage” and any message sent from the caller is received in the “onmessage” event.
var x =0
self.onmessage = function (e) {
for (i =0; i < 1000000000; i++)
{
x = i + x ;
}
self.postMessage(x);
} ;
Question 6.
How to terminate a Web worker?
Answer:
w.terminate( );
Question 7.
Why do we need HTML 5 server sent events?
Answer:
One of the common requirements in the Web world is getting updates from the server. Take the example of a stock ticker application where the browser has to take regular updates from the server for the recent stock value.
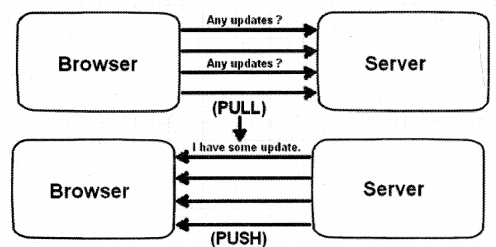
Now to implement this kind of requirement developers normally write some kind of PULL code that goes to the server and fetches data in certain intervals. Now PULL solution is good but it makes the network chatty with a lot of calls and also it adds load on the server.
So rather than PULL, it would be great if we can have some kind of PUSH solution. In simple words when the server has updated it will send updates to the browser client. That can be achieved by using “Server-Sent Events” as shown in Figure 9.21.
So the first thing the browser needs to do is connect to the server source which will send updates. Let’s say we have page “stock.aspx” which sends stock updates. So to connect to the page we need to use attach to the event source object as shown in the below code.
var source = new EventSource(“stock.aspx”);
We also need to attach the function where we will receive messages when server sends update. For that we need to attach function to the “onmessage” event as shown in the below code.
source.onmessage = function (event)
{
document.getElementByld("result").innerHTML += event.data + "<br>";
};
Now from the server-side we need to send events. Below are some lists of important events with command that needs to be sent from the server-side.
| Event | command |
| Send data to the client | Data: hello |
| Tell the client to retry in 10 seconds | Retry: 10000 |
| Raise a specific event with data | Event: success
Data: you are logged in. |
So now the “Total” field is removed and is the multiplication of Unit price * Qty.
Note: Fourth and Fifth Normal forms are left as homework to users.
Question 8.
What is denormalization?
Answer:
Denormalization is the process of putting one fact in numerous places (it’s vice-versa of normalization). Only one valid reason exists for denormalizing a relational design – to enhance performance or if we are doing data warehousing and data mining. The sacrifice to performance is that you increase redundancy in the database.
Question 9.
What are the different types of joins? What is the difference between them?
Answer:
INNER JOIN: Inner join shows matches only when they exist in both tables. For example, in the below SQL there are two tables Customers and Orders, and the inner join in made on Customers Customer id and Orders Customer id. So this SQL will only give you result with customers who have ordered. If the customer does not have an order, it will not display that record.
SELECT Customers. *, Orders. * FROM Customers INNER JOIN Orders ON Customers. CustomerlD =Orders. CustomerlD
LEFT OUTER JOIN: Left join will display all records in the left table of the SQL statement. In SQL below customers with or without orders will be displayed. Order data for customers without orders appears as NULL values. For example, you want to determine the amount ordered by each customer and you need to see who has not ordered anything as well. You can also see the LEFT OUTER JOIN as a mirror image of the RIGHT OUTER JOIN (Is covered in the next section) if you switch the side of each table.
SELECT Customers.*, Orders.* FROM Customers LEFT OUTER JOIN Orders ON Customers. CustomerlD -Orders.CustomerlD
RIGHT OUTER JOIN: Right join will display all records in the right table of the SQL statement. In SQL below all orders with or without matching customer records will be displayed. Customer data for orders without customers appear as NULL values. For example, you want to determine if there are any orders in the data with undefined CustomerlD values (say, after conversion or something like it). You can also see the RIGHT OUTER JOIN as a mirror image of the LEFT OUTER JOIN if you switch the side of each table.
SELECT Customers.*, Orders.* FROM Customers RIGHT OUTER JOIN Orders ON Customers. CustomerlD =Orders. CustomerlD
Question 10.
What is a candidate key?
Answer:
A table may have more than one combination of columns that could uniquely identify the rows in a table; each combination is a candidate key. During the database design, you can pick up one of the candidate keys to be the primary key. For example, in the Supplier table supplied and supplier name can be the candidate key but you will only pick up supplied as the primary key.
Question 11.
What are indexes and what is the difference between clustered and non-clustered?
Answer:
Indexes in SQL Server are similar to the indexes in books. They help SQL Server retrieve the data quickly.
There are clustered and non-clustered indexes. A clustered index is a special type of index that reorders the way in which records in the table are physically stored. Therefore, the table can have only one clustered index. The leaf nodes of a clustered index contain the data pages.
A non-clustered index is a special type of index in which the logical order of the index does not match the physical stored order of the rows on a disk. The leaf node of a non-clustered index does not consist of the data pages. Instead, the leaf nodes contain index rows.
Question 12.
How can you increase SQL performance?
Answer:
Following are tips that will increase your SQL performance:
- Every index increases the time takes to perform INSERTS, UPDATES, and DELETES, so the number of indexes should not be too much. Try to use a maximum of 4-5 indexes on one table, not more. If you have a read-only table, then the number of indexes may be increased.
- Keep your indexes as narrow as possible. This reduces the size of the index and reduces the number of reads required to read the index.
- Try to create indexes on columns that have integer values rather than character values.
- If you create a composite (multi-column) index, the orders of the columns in the key are very important. Try to order the columns in the key to enhance selectivity, with the most selective columns to the leftmost of the key.
- If you want to join several tables, try to create surrogate integer keys for this purpose and create indexes on their columns.
- Create a surrogate integer primary key (identity for example) if your table will not have many insert operations.
- Clustered indexes are more preferable to nonclustered if you need to select by a range of values or you need to sort results set with GROUP BY or ORDER BY.
- If your application will be performing the same query over and over on the same table, consider creating a covering index on the table.
- You can use the SQL Server Profiler Create Trace Wizard with “Identify Scans of Large Tables” trace to determine which tables in your database may need indexes. This trace will show which tables are being scanned by queries instead of using an index.
Question 13.
What is DTS?
Answer:
DTS (Data Transformation Services) is used to import data and while importing it helps us to transform and modify data. The name itself is self-explanatory DTS.
Question 14.
What is the fill factor?
Answer:
The ‘fill factor’ option specifies how full SQL Server will make each index page. When there is no free space to insert a new row on the index page, SQL Server will create a new index page and transfer some rows from the previous page to the new one. This operation Is called page splits. You can reduce the number of page splits by setting the appropriate fill factor option to reserve free space on each index page. The fill factor is a value from 1 through 100 that specifies the percentage of the index page to be left empty.
The default value for the fill factor is 0. It is treated similarly to a fill-factor value of 100, the difference in that SQL Server leaves some space within the upper level of the index tree for FILLFACTOR = 0. The fill factor percentage is used only at the time when the index is created. If the table contains read-only data (or data that very rarely changed), you can set the ‘fill factor’ option to 100. When the table’s data is modified very often, you can decrease the fill factor to 70% or whatever you think is best.
Question 15.
What is RAID and how does it work?
Answer:
Redundant Array of Independent Disks (RAID) is a term used to describe the technique of improving data availability through the use of arrays of disks and various data-striping methodologies. Disk arrays are groups of disk drives that work together to achieve higher data transfer and I/O rates than those provided by single large drives. An array is a set of multiple disk drives plus a specialized controller (an array controller) that keeps track of how data is distributed across the drives. Data for a particular file is written in segments to the different drives in the array rather than being written to a single drive.
For speed and reliability, it is better to have more disks. When these disks are arranged in certain patterns and are use a specific controller, they are called a (RAID) set. There are several numbers associated with RAID, but the most common are 1, 5, and 10.
RAID 1 works by duplicating the same write on two hard drives. Let us assume you have two 20 GB drives. In RAID 1, data is written at the same time to both drives. RAID 1 is optimized for fast writes.
RAID 5 works by writing parts of data across all drives in the set (it requires at least three drives). If a drive failed, the entire set would be worthless. To combat this problem, one of the drives stores a “parity” bit. Think of a math problem, such as 3 + 7 = 10. You can think of the drives as storing one of the numbers, and the 10 is the parity part. By removing any one of the numbers, you can get it back by referring to the other two, like this: 3 + X = 10. Of course, losing more than one could be evil. RAID 5 is optimized for reads.
RAID 10 is a bit of a combination of both types. It does not store a parity bit, so it is faster, but it duplicates the data on two drives to be safe. You need at least four drives for RAID 10. This type of RAID is probably the best compromise for a database server.
Note: It is difficult to cover complete aspect of RAID in this book. It’s better to take some decent SQL Server book for in detail knowledge, but yes from interview aspect you can probably escape with this answer.
Question 16.
What is the difference between DELETE and TRUNCATE TABLE?
Answer:
Following are differences between them:
- DELETE table can have criteria while TRUNCATE cannot.
- The TRUNCATE table does not invoke trigger.
- DELETE TABLE syntax logs the deletes thus make the delete operation slow. The TRUNCATE table does not log any information but it
logs information about deallocation of the data page of the table so the TRUNCATE table is faster as compared to delete the table.
Note: Thanks to all the readers for pointing out my mistake in the above question in my first edition. I had mentioned that the TRUNCATE table cannot be rolled back while the delete can be.
Question 17.
If locking is not implemented, what issues can occur?
Answer:
Following are the problems that occur if you do not implement locking properly in SQL Server.
Lost Updates: Lost updates occur if you let two transactions modify the same data at the same time, and the transaction that completes first is lost. You need to watch out for lost updates with the READ UNCOMMITTED isolation level. This isolation level disregards any type of locks, so two simultaneous data modifications are not aware of each other. Suppose that a customer has due of 2000$ to be paid. He/she pays 1000$ and again buys a product of 500$. Let’s say that these two transactions are now been entered from two different counters of the company.
Now both the counter user starts making, entry at the same time 10: 00 AM. Actually speaking at 10: 01 AM the customer should have 2000$-1000$+500 = 1500$ pending to be paid. But as said in lost updates the first transaction is not considered and the second transaction overrides it. So the final pending is 2000$+500$ = 2500$ I c hope the company does not lose the customer.
Non-Repeatable Read: Non-repeatable reads occur if a transaction is able to read the same row multiple times and gets a different value each time. Again, this problem is most likely to occur with the READ UNCOMMITTED isolation level. Because you let two transactions modify data at the same J time, you can get some unexpected results. For instance, a customer wants to book a flight, so the travel agent checks for the flight’s availability. The travel agent finds a seat and goes ahead to book the seat. While the travel agent is booking the seat, some other travel agent books the seat. When this travel agent goes to update the record, he gets an error saying that “Seat is already booked”. In short, the travel agent gets different status at different times for the seat.
Dirty Reads: Dirty reads are a special case of non-repeatable read. This happens if you run a report while transactions are modifying the data that you are reporting on. For example, there is a customer invoice report, which runs on 1: 00 AM (ante Meridien) in the afternoon and after that, all invoices are sent j to the respective customer for payments. Let us say one of the customers has 1000$ to be paid. Customer pays 1000$ at 1: 00 AM and at the same time report is run. Actually, the customer has no money pending but is still issued an invoice.
Phantom Reads: Phantom reads occur due to a transaction being able to read a row on the first read, but not being able to modify the same row due to another transaction deleting rows from the same table. Let us say you edit a record in the meantime somebody comes and deletes the record, you then go for updating the record which does not exist…Panicked.
Interestingly, the phantom reads can occur even with the default isolation level supported by SQL Server: READ COMMITTED. The only isolation level that does not allow phantoms is SERIALIZABLE, which ensures that each transaction is completely isolated from others. In other words, no one can acquire any type of locks on the affected row while it is being modified.
Question 18.
What are different transaction levels in SQL Server?
Answer:
Transaction Isolation level decides how is one process isolated from another process. Using transaction levels, you can implement locking in SQL Server.
There are four transaction levels in SQL Server:
READ COMMITTED: The shared lock is held for the duration of the transaction, meaning that no other transactions can change the data at the same time. Other transactions can insert and modify data in the same table, however, as long as it is not locked by the first transaction.
READ UNCOMMITTED: No shared locks and no exclusive locks are honored. This is the least restrictive isolation level resulting in the best concurrency but the least data integrity.
REPEATABLE READ: This setting disallows dirty and non-repeatable reads. However, even though the – locks are held on read data, new rows can still be inserted in the table, and will subsequently be interpreted by the transaction. v
SERIALIZABLE: This is the most restrictive setting holding shared locks on the range of data. This setting does not allow the insertion of new rows in the range that is locked; therefore, no phantoms are allowed. 4
Following is the syntax for setting transaction level in SQL Server. ;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
Question 19.
What are the different locks in SQL Server?
Answer:
Depending on the transaction level, six types of lock can be acquired on data:
Intent: The intent lock shows the future intention of SQL Server’s lock manager to acquire locks on a . specific unit of data for a particular transaction. SQL Server uses intent locks to queue exclusive locks, thereby ensuring that these locks will be placed on the data elements in the order the transactions were initiated. Intent locks come in three types: Intent Shared (IS), Intent Exclusive (IX), and Shared, with Intent Exclusive (SIX).
. IS locks indicate that the transaction will read some (but not all) resources in the table or page by placing shared locks.
IX locks indicate that the transaction will modify some (but not all) resources in the table or page by placing exclusive locks.
SIX locks indicate that the transaction will read all resources, and modify some (but not all) of them. 5 This will be accomplished by placing the shared locks on the resources read and exclusive locks on the rows modified. Only one SIX locks is allowed per resource at onetime; therefore, SIX locks prevent. other connections from modifying any data in the resource (page or table), although they do allow reading the data in the same resource.
Shared: Shared(S) locks allow transactions to read data with SELECT statements. Other connections are allowed to read the data at the same time; however, no transactions are allowed to modify data ‘ until the shared locks are released.
Update: Update(U) locks are acquired just prior to modifying the data. If a transaction modifies a row, then the update lock is escalated to an exclusive lock; otherwise, it is converted to a shared lock. Only one transaction can acquire update locks to a resource at one time. Using update locks prevents multiple connections from having a shared lock that wants to eventually modify a resource using an exclusive lock. Shared locks are compatible with other shared locks, but are not compatible with Update locks.
Exclusive: Exclusive(X) locks completely lock the resource from any type of access including reads. They are issued when data is being modified through INSERT, UPDATE, and DELETE statements.
Schema: Schema modification (Sch-M) locks are acquired when data definition language statements, such as CREATE TABLE, CREATE INDEX, ALTER TABLE, and so on are being executed. Schema stability locks (Sch-S) are acquired when store procedures are being compiled.
Bulk Update: Bulk Update (BU) locks are used when performing a bulk copy of data into a table with a TABLOCK hint. These locks improve performance while bulk copying data into a table; however, they reduce concurrency by effectively disabling any other connections to read or modify data in the table.
Question 20.
Can we suggest locking hints to SQL Server?
Answer:
We can give locking hints that help you override default decisions made by SQL Server. For instance, you can specify the ROWLOCK hint with your UPDATE statement to convince SQL Server to lock each row affected by that data modification. Whether it is prudent to do so is another story; what will happen if your UPDATE affects 95% of rows in the affected table? If the table contains 1000 rows, then SQL Server will have to acquire 950 individual locks, which is likely to cost a lot more in terms of, memory than acquiring a single table lock. So think twice before you bombard your code ROWLOCKS.
Question 21.
What is LOCK escalation?
Answer:
Lock escalation is the process of converting low-level locks (like rowlocks, page locks) into higher-level locks (like table locks). Every lock is a memory structure too many locks would mean, more memory being occupied by locks. To prevent this from happening, SQL Server escalates the many fine-grain locks to fewer coarse-grain locks. Lock escalation threshold was definable in SQL Server 6.5, but from SQL Server 7.0 onwards SQL Server dynamically manages it.
Question 22.
What are the different ways of moving data between databases in SQL Server?
Answer:
There are lots of options available; you have to choose your option depending upon your requirements. Some of the options you have are BACKUP/RESTORE, detaching and attaching databases, replication, DTS (Data Transformation Services), BCP (Bulk Copy Program), log shipping, INSERT…SELECT, SELECT…INTO, creating INSERT scripts to generate data.
Question 23.
What is the difference between a HAVING CLAUSE and a WHERE CLAUSE?
Answer:
You can use Having Clause with the GROUP BY function in a query and WHERE Clause is applied to each row before, they are part of the GROUP BY function in a query.
Question 24.
What is the difference between UNION and UNION ALL SQL syntax?
Answer:
UNION SQL syntax is used to select information from two tables. But it selects only distinct records from both the table, while UNION ALL selects all records from both the tables.
Note: Selected records should have same datatype or else the syntax will not work.
Question 25.
How can you raise custom errors from stored procedures?
Answer:
The RAISERROR statement is used to produce an ad hoc error message or to retrieve a custom message that is stored in the sys messages table. You can use this statement with the error handling code presented in the previous section to implement custom error messages in your applications. The syntax of the statement is shown here.
RAISERROR ((msg_id |msg_str }{, severity, state }
[, argument n ]]))
[ WITH option [,, ...n ] ]
A description of the components of the statement follows.
mug_id: The ID for an error message, which is stored in the error column in sys messages.
msg_str: A custom message that is not contained in sys messages.
Severity: The severity level associated with the error. The valid values are 0-25. Severity levels 0-18 can be used by any user, but 19-25 are only available to members of the fixed-server role sysadmin. When levels 19-25 are used, the WITH LOG option is required.
State A value that indicates the invocation state of the error. The valid values are 0-127. This value is not used by SQL Server.
Argument…
One or more variables are used to customize the message. For example, you could pass the current process ID (@@SPID) SO it could be displayed in the message.
WITH option,…
The three values that can be used with this optional argument are described here.
LOG: Forces the error to log in the SQL Server error log and the NT application log.
NOWAIT: Sends the message immediately to the client.
SETERROR: Sets @@ERROR to the unique ID for the message or 50, 000.
The number of options available for the statement makes it seem complicated, but it is actually easy to use. The following shows how to create an ad hoc message with a severity of 10 and a state of 1:
RAISERROR (‘An error occurred updating the Nonfatal table’, 10,1)
—Results—
An error occurred in updating the non-fatal table.
The statement does not have to be used in conjunction with any other code, but for our purposes, it will be used with the error handling code presented earlier. The following alters the
ps_NonFatal_iNSERT procedure to use RAISERROR:
USE tempdb
go
ALTER PROCEDURE ps_NonFatalJNSERT
@Column2 int =NULL AS.
DECLARE ©ErrorMsglD int
INSERT NonFatal VALUES (@Column2)
SET @ErrorMsgID =@@ERROR IF OErrorMsgID <>0 BEGIN
RAISERROR ('An error occured updating the NonFatal table', 10, 1)
END
When an error-producing call is made to the procedure, the custom message is passed to the client.
Question 26.
What is ACID fundamental?
Answer:
A transaction is a sequence of operations performed as a single logical unit of work. A logical unit of work must exhibit four properties, called the ACID (Atomicity, Consistency, Isolation, and Durability) properties, to qualify as a transaction:
Atomicity: A transaction must be an atomic unit of work; either all of its data modifications are performed or none of them is performed.
Consistency: When completed, a transaction must leave all data in a consistent state. In a relational database, all rules must be applied to the transaction’s modifications to maintain all data integrity.
isolation: Modifications made by concurrent transactions must be isolated from the modifications made by any other concurrent transactions. A transaction either see data in the state it was before another concurrent transaction modified it, or it sees the data after the second transaction has completed, but it does not see an intermediate state. This is referred to as serializability because it results in the ability to reload the starting data and replay a series of transactions to end up with the data in the same state it was in after the original transactions were performed.
Durability: After a transaction has completed, its effects are permanently in place in the system. The modifications persist even in the event of a system failure.
Question 27.
What are the different types of triggers in SQI Server?
Answer:
There are two types of triggers:
INSTEAD OF triggers: INSTEAD OF triggers fire in place of the triggering action. For example, if an INSTEAD OF UPDATE trigger exists on the Sales table and an UPDATE statement is executed against the Sales table, the UPDATE statement will not change a row in the sales table. Instead, the UPDATE statement causes the INSTEAD OF UPDATE trigger to be executed.
AFTER triggers: AFTER triggers execute following the SQL action, such as an insert, update, or delete. This is the traditional trigger that existed in SQL Server.
INSTEAD OF triggers are executed automatically before the Primary Key and the Foreign Key constraints are checked, whereas the traditional AFTER triggers are executed after these constraints are checked.
Unlike AFTER triggers, INSTEAD OF triggers can be created on views.
Question 28.
If we have multiple AFTER Triggers, can we specify sequence?
Answer:
If a table has multiple AFTER triggers, then you can specify which trigger should be executed first and which trigger should be executed last using the stored procedure sp_settriggerorder.
Question 29.
What is SQL injection?
Answer:
It is a Form of attack on a database-driven Website in which the attacker executes unauthorized SQL commands by taking advantage of insecure code on a system connected to the Internet, bypassing the firewall. SQL injection attacks are used to steal information from a database from which the data would normally not be available and/or to gain access to an organization’s host computers through the computer that is hosting the database.
SQL injection attacks typically are easy to avoid by ensuring that a system has strong input validation. As name suggest we inject SQL which can be relatively dangerous for the database. For example, this is a simple SQL
SELECT email, passwd, login_id, full_name FROM members WHERE email = 'x'
Now somebody does not put “x” as the input but puts “x ; DROP TABLE members;”. So the actual SQL which will execute is:
SELECT email, passwd, login_id, full_name FROM members - WHERE email = 'x'; DROP TABLE members;
Think what will happen to your database.
Question 30.
What is the difference between Stored Procedure and User-Defined Function?
Answer:
Following are some major differences between a Stored Procedure (SP) and User-Defined Functions (UDF):
- The main purpose of UDF was to increase reuse in the stored procedures. So you can call UDF from – a stored procedure and not vice versa.
- You cannot change any data using UDF while you can do everything with a stored procedure.
- UDF does not return output parameters while SP’s returns output parameters.
Note: SQL Server product is equivalently important from an interview point of view. I have dedicated a complete book “SQL Server Interview questions” to crack SQL Server. If you are interested in buying the book mail bpb@bol.net.in /bpb@vsnl.com or call the nearest BPB bookstall for my book. For shop phone numbers you can either see the back or front page of the book.