

Python has long been a key player in the fields of data science and machine learning. When we apply a model to a dataset, it is critical that we understand the model’s impact on the dataset in terms of accuracy and error rates. This aids us in comprehending the model’s impact on the dependent variable.
Loss functions provided by Python can be used for the same purpose. We can quickly understand the difference between predicted and actual data values using Loss functions. With these loss functions, we can simply obtain the error rate and, as a result, assess the model’s correctness.
4 Python Loss Functions That Are Frequently Used
- Mean Absolute Error
- Mean Square Error
- Root Mean Square Error
- Cross-Entropy Loss
1) Mean Absolute Error
Mean Absolute Error calculates the average of the absolute differences between the dataset’s predicted and actual data values. The mean_absolute_error() method in Python can be used to calculate the mean absolute error for any data range.
Example
Approach:
- Import mean_absolute_error function from metrics of the sklearn module using the import keyword.
- Import numpy module using the import keyword.
- Give the array of actual values as static input using the array() method and store it in a variable.
- Give the array of predicted values as static input using the array() method and store it in another variable.
- Calculate the mean absolute error for the given actual and predicted arrays using the mean_absolute_error() function and print the result.
- The Exit of the Program.
Below is the implementation:
# Import mean_absolute_error function from metrics of the sklearn
# module using the import keyword
from sklearn.metrics import mean_absolute_error
# Import numpy module using the import keyword
import numpy as np
# Give the array of actual values as static input using the array() method and
# store it in a variable
actul_arry = np.array([3, 5, 7, 2])
# Give the array of predicted values as static input using the array() method and
# store it in another variable
predctd_arry = np.array([0.7, 4, 3.4, 1.2])
# Calculate the mean absolute error for the given actual and predicted arrays using the
# mean_absolute_error() function and print the result
print("The mean absolute error for the given actual and predicted arrays is:")
print(mean_absolute_error(actul_arry, predctd_arry))
Output:
The mean absolute error for the given actual and predicted arrays is: 1.925
- Solved- TypeError: Dict_Values Object does not Support Indexing
- How to Convert a Python String to int
- How to Check if a Python Package is Installed or Not?
2)Mean Square Error
The average of the square of the difference between predictions and actual observations is used to calculate mean square error (MSE). We can express it mathematically as follows:

where
n is the number of data points
 = Actual values
= Actual values
 = Predicted values
= Predicted values
Example
Approach:
- Import mean_squared_error function from metrics of the sklearn module using the import keyword.
- Import numpy module using the import keyword.
- Give the array of actual values as static input using the array() method and store it in a variable.
- Give the array of predicted values as static input using the array() method and store it in another variable.
- Calculate the Mean Square Error(MSE) for the given actual and predicted arrays values using the mean_squared_error() function by setting squared = True as an argument and print the result.
- The Exit of the Program.
Below is the implementation:
# Import mean_squared_error function from metrics of the sklearn
# module using the import keyword
from sklearn.metrics import mean_squared_error
# Import numpy module using the import keyword
import numpy as np
# Give the array of actual values as static input using the array() method and
# store it in a variable
actul_arry = np.array([3, 5, 7, 2])
# Give the array of predicted values as static input using the array() method and
# store it in another variable
predctd_arry = np.array([0.7, 4, 3.4, 1.2])
# Calculate the Mean Square Error(MSE)for the given actual and predicted arrays values using the
# mean_squared_error() function by setting squared = True as an argument and print the result
print("The MSE for the given actual and predicted arrays is:")
print(mean_squared_error(actul_arry, predctd_arry, squared = True))
Output:
The MSE for the given actual and predicted arrays is: 4.9725
3)Root Mean Square Error
Root Mean Square Error is defined as the square root of the average of the squared differences between the estimated and actual value of the variable or feature.
The square root of Mean Square error is used to determine Root Mean Square Error (RMSE). We can express it mathematically as follows:
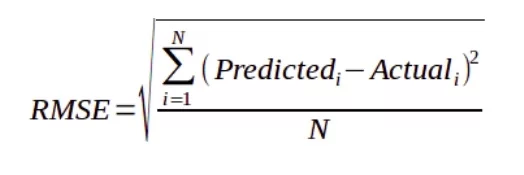
We calculate the difference between the predicted and actual values of the dataset using Root Mean Square Error. Following that, we compute the square of the differences and apply the mean function to it. The NumPy module and the mean_squared_error() method will be used jointly in this case, as seen below. With the mean_squared_error() function, we need to set the squared parameter to False, for it to pick up and calculate RMSE. If set to True, MSE will be calculated.
Example
Approach:
- Import mean_squared_error function from metrics of the sklearn module using the import keyword.
- Import numpy module using the import keyword.
- Give the array of actual values as static input using the array() method and store it in a variable.
- Give the array of predicted values as static input using the array() method and store it in another variable.
- Calculate the Root Mean Square Error(RMSE) for the given actual and predicted arrays values using the mean_squared_error() function by setting squared = False as an argument and print the result.
- The Exit of the Program.
Below is the implementation:
# Import mean_squared_error function from metrics of the sklearn
# module using the import keyword
from sklearn.metrics import mean_squared_error
# Import numpy module using the import keyword
import numpy as np
# Give the array of actual values as static input using the array() method and
# store it in a variable
actul_arry = np.array([3, 5, 7, 2])
# Give the array of predicted values as static input using the array() method and
# store it in another variable
predctd_arry = np.array([0.7, 4, 3.4, 1.2])
# Calculate the Root Mean Square Error(RMSE)for the given actual and predicted arrays values using the
# mean_squared_error() function by setting squared = False as an argument and print the result
print("The RMSE for the given actual and predicted arrays is:")
print(mean_squared_error(actul_arry, predctd_arry, squared = False))
Output:
The RMSE for the given actual and predicted arrays is: 2.229910312097776
4)Cross-Entropy Loss
RMSE, MSE, and MAE are commonly used to solve regression problems. The cross-entropy loss function is widely employed in problem statements of the Classification type. It allows us to define the error/loss rate for classification issues against a categorical data variable.
The Python sklearn package includes the log loss() function, which may be used to manage and calculate the error rate for classification/categorical data variables.
Example
# Import log_loss function from metrics of the sklearn # module using the import keyword from sklearn.metrics import log_loss # Give the list of ebtropy values as static input using the array() method and # store it in a variable rslt = log_loss(["No", "Yes", "Yes", "No", "Yes"],[[8, 10], [20, 15], [6, 4], [25, 35], [18, 20]]) # Print the above result print(rslt)
Output:
0.6931471805599453