
We have compiled most frequently asked .NET Interview Questions which will help you with different expertise levels.
.NET Interview Questions on Basic .NET Framework
Question 1.
What is an IL code? (B)What Is an IL?
Answer:
IL code is a partially compiled code.
Note: Half compiled means this code is not yet compiled to machine/CPU (Central Processing Unit) specific instructions.
Question 2.
Why is IL code not fully compiled?
Answer:
We do not know in what kind of environment the .NET code will run. In other words, we do not know what can be the Operating System (OS), CPU configuration, machine configuration, security configuration, etc. So the IL code is half compiled and on run-time, this code is compiled to machine-specific using the environmental properties (CPU, OS, machine configuration, etc).
Question 3.
Who compiles the IL code and how does it work?
Answer:
IL code is compiled by JIT (Just-in-time) compiler.
Question 4.
How does JIT compilation work?
Answer:
JIT compiles the code just before execution and then saves this translation in memory. Just before execution JIT can compile a profile, per function, or a code fragment.
Question 5.
What are the different types of JIT? (P)What are the different types of JIT?
Answer:
In Microsoft .NET there are three types of JIT compilers:
- Normal-JIT (Default): Normal-JIT compiles only those methods that are called at runtime. These methods are compiled the first time they are called, and then they are stored in the cache. When the same methods are called again, the compiled code from the cache is used for execution.
- Econo-JIT: Econo-JIT compiles only those methods that are called at runtime. However, these compiled methods are not stored in the cache so that RAM (Random Access Memory) can be utilized in an optimal manner.
- Pre-JIT: Pre-JIT compiles complete source code into native code in a single compilation cycle. This is done at the time of deployment of the application. We can implement Pre-JIT by using ngen.exe (The Native Image Generation).
Normal-JIT is the default implementation and it produces optimized code. Econo- JIT just replaces IL instruction with its native counterpart. It does not do any kind of optimization. Econo- JIT does not store the compiled code in the cache so it requires less memory.
The choice of Normal-JIT and Econo-JIT is decided internally. Econo-JIT is chosen when devices have
limited memory and CPU cycle issues like Windows CE-powered devices. When there is no memory crunch and CPU power is higher than Normal-JIT is used.
Pre-JIT is implemented by using ngen.exe which is explained in the next question.
Question 5.
What is Native Image Generator (Ngen.exe)?
Answer:
Ngen stores full compiled .NET native code into the cache. In other words, rather than dynamically compiling the code on runtime a full image of natively compiled code is stored in cache while installing the application. This leads to better performance as the assembly loads and executes faster.
In order to install full compiled native code in the cache, we can execute the below command line from your Visual Studio command prompt.
ngen.exe install <assemblyname>
Question 6.
So does it mean that NGEN.EXE will always improve performance?
Answer:
No, it’s not always necessary that ngen.exe produces optimized code because it uses the current environment’s parameters which can change over a period of time. For instance, a code compiled in the Windows XP environment will not be the optimized code to run under Windows 2008 server. So we need to test once with ‘ngen’ and without ‘ngen’ to conclude if really the performance increases.
Question 7.
Is it possible to view the IL code?
Answer:
Yes by using ILDASM (IL Disassembler) simple tool we can view an IL code of a DLL (Dynamic Link Library) or EXE (Executable). In order to view IL code using ILDASM, go to Visual Studio command prompt and run “ILDASM.EXE”. Once ILDASM is running you can view the IL code,
Question 8.
What is a CLR?
CLR (Common Language Runtime) is the heart of.NET framework and it does four primary tasks:
- Garbage collection
- CAS (Code Access Security)
- CV (Code Verification)
- IL to Native translation.
Note: There are many other uses of CLR but I have kept it short for interview point of view.
In the further section, we will explain these questions briefly.
Question 9.
What is the difference between managed and unmanaged code?
Answer:
Code that executes under the CLR execution environment is called managed code. Unmanaged code executes outside the CLR boundary. Unmanaged code is nothing but code written in C++, VB6, VC++, etc. Unmanaged codes have their own environment in which the code runs and it’s completely outside the control of CLR.
Question 10.
What is a garbage collector?
Answer:
The garbage collector is a feature of CLR which cleans unused managed (it does not clean unmanaged objects) objects and reclaims memory. It’s a background thread that runs continuously and at specific intervals, it checks if there are any unused objects whose memory can be claimed.
Note: GC does not claim memory of unmanaged objects.
Note: Garbage collector is one of the very important interview topics due to complexity of
generations, double GC loop because of destructor, and the implementation of finalizing
and dispose pattern. So please go through the video of “What are Garbage collection,
Generation, Finalize, Dispose and Idisposable?” to ensure that you understand the fundamentals clearly.
Question 11.
What are generations in Garbage Collector (Gen 0, Gen 1, and Gen 2)?
Answer:
Generations define the age of the object. There are three generations:
- Gen 0: When an application creates fresh objects they are marked as Gen 0.
- Gen 1: When GC is not able to clear the objects from Gen 0 in the first round it moves them to Gen – 1 bucket.
- Gen 2: When GC visits Gen 1 objects and it is not able to clear them it moves them Gen 2.
Generations are created to improve GC performance. The garbage collector will spend more time on Gen 0 objects rather than Gen 1 and Gen 2 thus improving performance.
Note: More the objects in Gen 0, the more your application is stable.
Question 12.
Garbage collector cleans managed code, how do we clean unmanaged code?
Answer:
Garbage collector only claims managed code memory. For unmanaged code, you need to put clean up in destructor / finalize.
Question 13.
But when we create a destructor the performance falls down?
Answer:
Yes, when we define a destructor, the garbage collector does not collect these objects in the first round. It moves them to Gen 1 and then reclaims these objects in the nex+ cycle.
As more objects are created in Gen 1 the performance of the application falls down because more memory is consumed.
Question 14.
So how can we clean unmanaged objects and also maintain performance?
Answer:
We need to follow the below steps:
- Implement IDisposable interface and implement the Dispose function.
- In Dispose function calls the “GC . SuppressFinalize” method.
- At the client-side ensure that the “Dispose” function is called when the object is no more required.
Below goes the code, this is also called “Finalize and Dispose of pattern”. This ensures that your objects are created in Gen 0 rather than Gen 1. “GC. SuppressFinalize” tells the garbage collector to not worry about destructor and destroy the objects in the first call itself.
class clsMyClass: IDisposable
{
-clsMyClass( )
{
// In case the client forgets to call
// Dispose, destructor will be invoked for
Dispose(false);
}
protected virtual void Dispose(bool disposing)
{
if (disposing)
{
// Free managed objects.
}
// Free unmanaged objects
}
public void Dispose()
{
Dispose(true);
// Ensure that the destructor is not called
GC.SuppressFinalize(this);
}
}
Note: Please do go through the videos of “What is IDisposable interface and finalize dispose
pattern in GC?” in which we have actually shov</ed how generation performance increases
by using Finalize and Dispose pattern.
Question 15.
Can we force the garbage collectors to run? (l) Can we force the garbage collectors to run?
Answer:
“System.GC.Collect ( )” forces garbage collector to run. This is not a recommended practice but can be used if situations arise.
Question 16.
What is the difference between finalize and dispose?
Answer:
- Finalize is a destructor and Dispose is a function that is implemented via the ‘ iDisposable’ interface.
- Finalize is non-deterministic since it’s called by the garbage collector. Dispose is a function and needs to be called by the client
for clean up. In other Finalize is automatically called by the garbage collector while Dispose needs to be called forcefully.
Note: As a good practice Finalize and Dispose are used collectively because of the double
garbage collector loop. You can talk about this small note. You can also talk about the above two differences.
Question 17.
What is CTS?
Answer:
In .NET there are lots of languages like C#, VB.NET, VF.NET, etc. There can be situations when we want to code in one language to be called in another language. In order to ensure smooth communication between these languages, the most important thing is that they should have a common type system. CTS (Common Types System) ensures that data types defined in two different languages get compiled to a common data type.
So “integer” data type in VB6 and i”int” data type in C++ will be converted to System. int32, which is data type of CTS.
Note: If you know COM programming, you would know how difficult it is to interface the VB6 application
with the VC++ application. As the data types of both languages did not have a common ground where
they can come and interface, having CTS interfacing is smooth.
Question 18.
What is a CLS (Common Language Specification)?
Answer:
CLS is a subset of CTS. CLS is a specification or set of rules or guidelines. When any programming language adheres to this set of rules it can be consumed by any .NET language.
For instance one of the rules which makes your application CLS non-compliant is when you declare your methods members with the same name and with only case differences in C#. You can try this. Create a simple class in C# with the same name with only case differences and try to consume the same in VB.NET, it will not work.
Question 19.
What is an Assembly?
Answer:
Assembly is a unit of deployments like EXE or a DLL.
Question 20.
What are the different types of Assembly?
Answer:
There are two types of assembly: Private and Public assembly. A private assembly is normally used by a single application and is stored in the application’s directory, or a sub-directory beneath. A shared assembly is stored in the global assembly cache, which is a repository of assemblies maintained by the .NET runtime.
Shared assemblies are needed when we want the same assembly to be shared by various applications on the same computer.
Question 21.
What is Namespace?
Answer:
Namespace does two basic functionalities:
- It logically groups classes, for instance, System. Web. UI namespace logically groups Ul-related features like text boxes, list control, etc.
- In an Object-Oriented world, many times it is possible that programmers will use the same class name. Qualifying NameSpace with class names avoids this collision.
Question 22.
What is the difference between namespace and assembly?
Answer:
Following are the differences between namespace and assembly:
- Assembly is the physical grouping of logical units, whereas namespace logically groups classes.
- The namespace can span multiple assemblies while the assembly is a physical unit like EXE, DLL, etc.
Question 23.
What is ILDASM?
Answer:
ILDASM is a simple tool that helps you to view the IL code of a DLL or EXE. In order to view IL code using ILDASM, go to Visual Studio command prompt and run “ILDASM.EXE”. Once ILDASM is running you view the IL code. ‘
Question 24.
What is Manifest?
Assembly metadata is stored in Manifest. Manifest contains metadata that describes the following things:
- Version of assembly
- Security identity
- Scope of the assembly
- Resolve references to resources and classes
The assembly manifest is stored in the DLL itself.
Question 25.
Where is the version information stored of an assembly?
Answer:
Version information is stored in assembly inside the manifest.
Question 26.
Is versioning applicable to private assemblies?
Answer:
Yes, versioning is applicable to private assemblies also.
Question 27.
What is the use of strong names?
Answer:
Note: This question can also be asked in two different ways: What are weak references and strong
references or How do you create a strong name for a .NET assembly
When we talk about the .NET application it has two parts one is the class library or the DLL and the other the consumer like windows Ul, etc., using this DLL.
If the consumer identifies the DLL library by namespace and class names it’s called a weak reference. It’s very much possible in a deployment environment someone can delete the original class library and fake a similar class library with the same class name and namespace name.
A strong name is a unique name that is produced by the combination of the version number, culture information, public key, and digital signature. No one can fake this identity or generate the same name.
So your consumer or Ul will refer to the class library with strong names rather than class and namespace names. In order to create the strong name, right-click on the Class library, click on Properties, click on the Signing* tab, and click on the New menu to generate strong names as shown in Figure 2.1.

Question 28.
What is Delay signing?
Answer:
The whole point about strong names is to ensure that the clients (Ul, External components, etc.) who are consuming the DLL knows that the DLL was published from a valid source. This authenticity is verified by using strong names. Strong name protection is good from external hackers but what if your own developers think of doing something mischievous.
That’s why delayed signing helps. The strong name key has two keys: a public key and a private key. You only share the public key with your developers so that they can work seamlessly. The private key is stored in a secured location and when the DLL is about to be deployed on production the key is injected for further security.
Question 30.
What is GAC?
Answer:
GAC (Global Assembly Cache) is where all shared .NET assembly resides. GAC is used in the following situations:
- If the application has to be shared among several application which is in the same computer.
- If the assembly has some special security, requirements like only administrators can remove the assembly. If the assembly is private then a simple delete process of the assembly file will remove the assembly.
Question 31.
How to add and remove an assembly from GAC?
Answer:
You can use the ‘GacUtil’ tool which comes with Visual Studio. So to register an assembly into GAC go to “Visual Studio Command Prompt” and type “gacutil -i (assembly name)”, where (assembly name) is the DLL name of the project.
Once you have installed the assembly the DLL can be seen in ‘c: \windows\assemblyV folder.
When we have many DLLs to be deployed we need to create a setup and deployment package using windows installer. So the common way of deploying GAC DLL in production is done by using a windows installer.
Question 32.
If we have two versions of the same assembly in GAC how to we make a choice?
Answer:
When we have two versions of the same assembly in GAC we need to use binding redirect tag and specify the version we want to use in the new version property as shown in the below “app.config” file.
<configuration> <runtime> <assemblyBinding xmlns="urn: schemas-microsoft-com: asm.vl"> <dependentAssembly> <assemblyldentity name="ComputerName" publicKeyToken="cfc68d722cd6al64'' /> <publisherPolicy apply="yes" /> <bindingRedirect oldVersion="l.1.0.0" newVersion="1.0.0.0" /> </dependentAssembly> </assemblyBinding> </runtime> </configuration>
Question 33.
What is Reflection and why we need it?
Answer:
Reflection is needed when you want to determine/inspect the contents of an assembly. For example, look at your Visual Studio Editor IntelliSense, when you type (dot) before any object, it gives you all members of the object. This is possible because of reflection.

Reflection also goes one step further; it can also invoke a member which is inspected. For instance, if the reflection detects that there is a method called “GetChanges” in an object as shown in Figure 2.2. We can get a reference to that method instance and invoke the same on runtime.
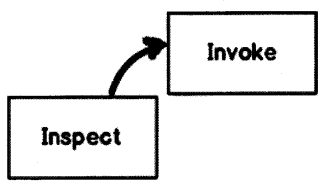
In simple words reflection passes through two steps: “Inspect” and “Invoke” (optional) as shown in Figure 2.3. The “Invoke” process is optional.
Question 34.
How do we implement reflection?
Answer:
Implementing reflection in C# is a two-step process, first, get the “type” of the object and then use the type to browse members like “methods”, “properties”, etc.
Step 1: The first step is to get the type of object. So, for example, you have a DLL called “ClassLibrary1.dll” which has a class called “ClassT’. We can use the “Assembly” class (belongs to System. Reflection namespace) to get a reference to the type of object. Later we can use “Activator. Createlnstance” to create an instance of the class. The “GetTypeO” function helps us to get a reference to the type of object. ,
var myAssembly = Assembly.LoadFile(@"C: \ClassLibraryl.dll");
var myType = myAssembly.GetType("ClassLibraryl.Classl");
dynamic objMyClass = Activator.Createlnstance(myType);
// Get the class type
Type parameterType = objMyClass.GetType( );
Step 2: Once we have referenced the type of the object we can then call “GetMembers” or “GetProperties” to browse through the methods and properties of the class.
// Browse through members
foreach (Memberlnfo objMemberlnfo in parameterType.GetMembers( ))
(Console.WriteLine(objMemberlnfo.Name);}
// Browse through properties.
foreach (Propertylnfo objPropertyInfo in parameterType.GetProperties( ))
{Console.WriteLine(objPropertylnfo.Name);}
In case you want to invoke the member which you have inspected you can use ” invokeMember” to invoke the method. Below is the code for the same.
parameterType.InvokeMember("Display",BindingFlags.Public|
BindingFlags.NonPublic | BindingFlags.InvokeMethod|
BindingFlags.Instance, null, objMyClass, null);
Question 35.
What are the practical uses of reflection?
- If you are creating an application like Visual Studio editors where you want to show the internal of an object by using IntelliSense.
- In unit testing sometimes we need to invoke private methods. It checks whether private members are proper or not.
- Sometimes we would like to dump properties, methods, and assembly references to a file or probably show it on a screen.
Question 36.
What is the use of dynamic keywords?
Answer:
Programming languages can be divided into two categories strongly typed and dynamically typed. Strongly typed languages are those where the checks happen during compile-time while dynamic languages are those where type checks are bypassed during compile-time. In dynamic language object types are known only during runtime and type checks are activated only at runtime.
So we would like to take advantage of both the world. Because many times we do not know object type until the code is executed. In other words, we are looking at something like a dynamically statically typed kind of environment. That’s what dynamic keyword helps us with.
If you create a variable using the “dynamic” keyword and if you try to see members of that object you will get a message as shown in Figure 2.5 “This operation will be resolved at runtime”.

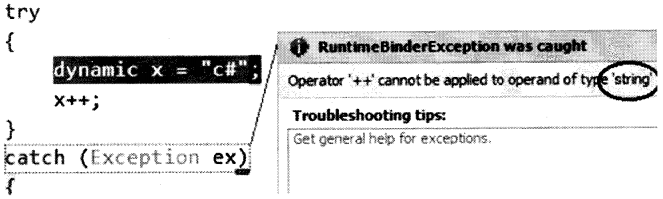
Now try the below code out. In the below code I have created a dynamic variable that is initialized with string data. And in the second line, I am trying to have fun by trying to execute a numeric incremental operation. So what will happen now?…. think.
dynamic x = “c#”;
x++;
Now, this code will compile successfully. But during runtime, it will throw an exception complaining that the mathematical operations cannot be executed on the variable as it is a string type as shown in Figure 2.6. In other words, during runtime, the dynamic object gets transformed from general data type to specific data type (ex: string for the below code).
Question 37.
What are the practical uses of dynamic keywords?
Answer:
One of the biggest practical uses of dynamic keywords is when we operate on MS Office components via Interop.
So for example, if we are accessing Microsoft Excel components without dynamic keywords, you can see how complicated the below code is. Lots of casting happening in the below code, right.
// Before the introduction of dynamic. Application excelApplication = new ApplicationO; ((Excel.Range)excelApp.Cells[1, l]).Value2 = "Name"; Excel.Range range2008 = (Excel.Range)excelApp.Cells[1, 1];
Now, look at how simple the code becomes by using the dynamic keyword. No casting needed and during runtime type checking also happens.
// After the introduction of dynamic, the access to the Value property and // the conversion to Excel. The range is handled by the runtime COM binder, dynamic excelApp = new ApplicationO; excelApp.Cells[1, 1].Value = "Name"; Excel.Range range2010 = excelApp.Cells[1, 1];
Question 38.
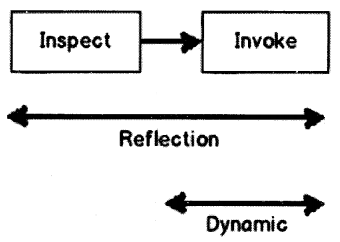
What is the difference between Reflection and Dynamic?
Answer:
- Both reflection and dynamic are used when we want to operate on an object during runtime.
- Reflection is used to inspect metadata (data about data) of an object. It also has the ability to invoke members of an object on runtime.
- Dynamic is a keyword that was introduced in .NET 4.0. It evaluates object calls during runtime. So until the method calls are made compiler is least bothered if those methods/properties exist or not.
- Dynamic uses reflection internally. It caches the method calls made thus improving performance to a certain extent.
- Reflection can invoke both public and private members of an object while dynamic can only invoke public members.
Below is the detailed comparison Table which shows in which scenario they are suited.
| E-mail Address | xyz@pqr.com | Email address data starts with some characters followed by”@” and then a “.” And finnaly the domin extension. |
| Phone number | 901-9090-909023
909-999-1202920 |
Phone number data starts with an international code followed by a region code and then the phone number. |
Figure 2.7 shows visually what reflection can do and what dynamic keywords can do.
Question 39.
Explain the difference between early binding and late binding.
Answer:
Early binding or early bound means the target methods, properties, and functions are detected and checked during compile-time. If the method/function or property does not exist or has data type issues then the compiler throws an exception during compile-time.
Late binding is the opposite of early binding. Methods, properties, and functions are detected during runtime rather than compile-time. So if the method, function, or property does not exist during runtime application will throw an exception.
Note: In simple words, everything is early bound until you are using reflection or dynamic keyword.
Question 40.
What is the difference between var and dynamic keywords?
Answer:
Note: Comparing VAR and Dynamic keyword is like comparing Apples and oranges. Many
people confuse VAR with the variant datatype of VB6 and there’s where the interviewer
tries to confuse you. But there is absolutely no connection of var C# keyword with a variant of VB6.
var is early bound (statically checked) while dynamic is late-bound (dynamically evaluated).
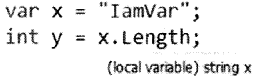
var keyword looks at your right-hand side data and then y = X. Length; during compile-time, it decides the left-hand side data type. (local variable) string x In other words var keyword just saves you typing a lot of things.
On the other hand, the dynamic keyword is for a completely different purpose. Dynamic objects are evaluated during runtime. For instance in the below code the “Length” property exists or not is evaluated during runtime.
dynamic z = “Dynamic”; y = z. Length; // Is Length present or not checked during runtime
If for some reason you mistype the “Length” property to “length” (Small “I”) you would end up into a runtime exception as shown in figure 2.9.

So in short sentence var does static check while dynamic evaluates and checks during runtime.
Question 41.
Explain term type safety and casting in C#.
Answer:
There are two types of languages one which is type-safe and one which is not. Type safety means preventing type errors. Type error occurs when the data type of one type is assigned to another type unknowingly and we get undesirable results.
For instance, JavaScript is not a type-safe language. In the below code “num” is a numeric variable and “str” is a string. Javascript allows me to do “num + str”, now guess will it do arithmetic or concatenation.
Now the result of the below code is “55” but the important point is the confusion created what kind of operation it will do.
This is happening because JavaScript is not a type-safe language. It allows setting one type of data to the other type without restrictions. ,
<script> var num = 5; // numeric var str = "5"; // string var z = num + str; // arthimetic or concat???? alert(z); // displays "55" . </script>
C# is a type-safe language. It does not allow one data type to be assigned to another data type. The below code does not allow the “+” operator on different data types.

But in certain scenarios, we would like to convert the data type to achieve the given results that’s where we need to do conversion or casting. The next question talks about the same in detail.
Question 42.
Explain casting, implicit conversion, and explicit conversion.
Answer:
Note: Some interviewers term this conversion as casting and some just prefer to call it as conversion,
at the end of the day they mean the same thing.
To understand the implicit and explicit conversion of data types first let’s try to understand the typecasting concept. Typecasting is a mechanism where we convert one type of data to another type.
For example, below is a simple code where we want to move the integer (value without decimals) value to a double (value with decimals). When we try to move double data type to integer data typecasting occurs. Casting is also termed conversion.
int i = 100;
doubled = 0;
d = i; // casting
In the above example, there is no loss of data. In other words when we moved 100 integer values to double we get the 100 value as it. This is termed implicit conversion/casting.
Now consider the below code where we are trying to move a double to an integer. In this scenario, in integer, only 100 will be received and decimals will be removed. You can also see I need to explicitly specify that we need to convert into an integer. This is termed explicit conversion.
doubled = 100.23;
int i = 0;
i = (int) d; // this will have 100, 0.23 will truncated.
Question 43.
What are stack and heap?
Answer:
Stack and heap are memory types in an application. Stack memory stores data types like int, double, Boolean, etc., while heaping stores data types like string and objects.
For instance when the below code runs, the first two variables, i.e., “i” and “y” are stored in a stack and the last variable “o” is stored in heap.
void MyFunction()
{
int i = 1; // This is stored in stack,
int y = i; // This is stored in stack,
object o = null; // This is stored in heap.
}
// after this end the stack variable memory space is reclaimed while // the heap memory is reclaimed later by the garbage collector.
Question 44.
What are Value types and Reference types?
Answer:
Value types contain actual data while reference types contain pointers and the pointers point to the actual data. Value types are stored on the stack while reference types are stored on the heap. Value types are your normal data types like int, bool, double and reference types are all objects.
Question 45.
What is the concept of Boxing and Unboxing?
Answer:
When a value type is moved to a reference type it’s called boxing. The vice-versa is termed unboxing.
Below is a sample code of boxing and unboxing where integer data type is converted into an object and then vice versa.
int i = 1 ;
object obj = i; // boxing
int j = (int) obj; // unboxing
Question 46.
How performance is affected due to boxing and unboxing?
Answer:
When boxing and unboxing happens the data needs to jump from stack memory to heap and vice-versa which is a bit of a memory-intensive process. As a good practice avoid boxing and unboxing wherever possible.
- The first thing is it really necessary to use boxing and unboxing. If it’s unavoidable like moving data from Ul text boxes to internal C# data types, then go for it.
- Try to see if you can use generics and avoid it.
Note: We leave this as homework to the reader’s compile, a DLL obfuscates it using
“Dotfuscator Community Edition” which comes with Visual Studio.NET, and
try viewing the same using ILDASM.
String s = “C# interview questions”;
string s = “C# interview questions”;
- object: System.Object
- string: System. String
- bool: System.Boolean
- byte: System.Byte
- byte: System. SByte
- short: System. Inti6
- ushort: System.UIntl6
- int: System. Int32
- uint: System.UInt32
- long; System. Int64
- ulong: System.UInt64
- float: System. Single
- double: System.Double
- decimal: System.Decimal
- char: System. char
string s = String. ToUpper( ) ;
throw new Exception (“Customer code cannot be more than 10'’);
try
{
// This section will have the code which
// which can throw exceptions.
}
catch(Exception e)
{
// Handle what you want to
// do with the exception
label.text = e.Message;
}
Question 56.
public class MyOwnException: ApplicationException
{
private string messageDetails = String.Empty;
public DateTime ErrorTimeStamp {get; set;}
public string CauseOfError {get; set;}
public MyOwnException(){ }
public MyOwnException(string message,
string cause, DateTime time)
{
messageDetails = message;
CauseOfError - cause;
ErrorTimeStamp = time;
}
// Override the Exception. Message property.
public override string Message
{
get
{
return string.Format("This is my own error message");
}
}
}
Question 59.
- Arrays are fixed in size while ArrayList is resizable.
- Arrays are strongly typed, in other words, when you create an array it can store only one data type data. ArrayList can store any datatype.
// Array definition int[ ] str = new int[10]; // Arraylist definition ArrayList MyList = new ArrayList( );
Question 63.
What are hashtable collections?
Answer:
In ArrayList or array if we have to access any data we need to use the internal index id generated by the ArrayList collection. For instance, the below code snippet shows how the internal id is used to fetch data from ArrayList.
In actual scenarios, we hardly remember internal id’s generated by collection we would like to fetch the data by using some application-defined key. There’s where hashtable comes into the picture.
string str = MyList[1]. ToString( );
Hashtable helps to locate data using keys as shown below. When we add data to hashtable it also has a provision where we can add keys with the data. This key will help us to fetch data later using a key rather than using internal indexes id’s generated by collections.
objHashtable.Add(“p001 ”, “MyData”);
This key is converted in to numeric hash value which is mapped with the key for the quick lookup.
Question 64.
What are Queues and stack collection?
Answer:
Queues are collection which helps us to add object and retrieve them in the manner they were added. In other word queues helps us to achieve the First In First Out (FIFO) collection behavior.
Stack collection helps us to achieve First In Last Out (FILO) behavior.
Question 65.
Can you explain generics in .NET?
Answer:
Generics help to separate logic and data type to increase reusability. In other words, you can create a class whose data type can be defined on runtime.
For instance below is a simple class “Class1” with a “Compare” function created using generics. You can see how the unknown data type is put in greater than and less than a symbol. Even the Compare method has the unknown data type attached.
public Class Classl<UNNKOWDATATYPE>
{
public bool Compare(UNNKOWDATATYPE vl, UNNKOWDATATYPE v2 )
{
if (v1.Equals(v2))
{
return true;
}
else
{
return false;
}
}
}
During runtime, you can define the data type as shown in the below code snippet.
Class1<int> obj = new Class1<int>( );
bool b = obj.Compareme(1, 2); // This compares numeric
Class1<string> obj1 = new Classl<string>( );
bool bl = obj1.Compareme("shiv", "shiv"); // This does string comparison
Question 66.
Explain generic constraints and when should we use them.
Answer:
Generic’s helps to decouple logic from the data type. But many times some logic is very specific to specific data types.
public class CompareNumeric<UNNKOWDATATYPE>
{
public bool Compareme(UNNKOWDATATYPE v1, UNNKOWDATATYPE v2)
{
if (v1>v2)
{return true;}
else
{return false;}
}
}
The example above is a simple generic class that does a comparison if one number is greater than another number. Now the greater and less than comparison is very specific to numeric data types. This kind of comparison cannot be done on non-numeric types like strings.
So if some uses the classes with “int” type it is perfectly valid.
CompareNumeric<int> obj = new CompareNumeric<int>( ); bool boolgreater = obj.Compare(10, 20);
If someone uses it with the “double” data type again perfectly valid.
CompareNumeric<double> obj = new CompareNumeric<double>( ); bool boolgreater = obj. Compare(100.23, 20.45);
But using string data type with this logic will lead undesirable results. So we would like to restrict or put a constraint on what kind of types can be attached to a generic class this is achieved by using “generic constraints”.
CompareNumeric<string> obj = new CompareNumeric<string>( ); bool boolgreater = obj.Compare(“interview’\ “interviewer”);
A generic type can be restricted by specifying data type using the “where” keyword after the generic class as shown in the code given below. Now if any client tries to attach “string” data type with the below class it will not allow, thus avoiding undesirable results.
public class CompareNumeric<UNNKOWDATATYPE> where UNNKOWDATATYPE; int, double
{
}
Question 67.
Can you explain the concept of the generic collection?
Answer:
Arraylist, Stack, and Queues provide collections that are not type safe. This leads two problems first it is not type-safe, and second it leads to boxing and unboxing.
By using generics we can have type safety, and also we can avoid boxing and unboxing. Below is a simple code snippet that shows a strongly typed list of type integers and strings.
List<int> obj; .
obj.add(l); // you can only add integers to this list
List<string> obj;
obj.add("shiv"); // you can only add string to this list
Question 68.
What is the difference between dictionary and hashtable?
Answer:
A Dictionary collection is a generic collection equivalent to a hashtable. Hashtable allows you to add keys and values of any type (i.e., objects). This leads to two problems one is boxing and unboxing issues and second it’s not strongly typed.
// Creates a strongly typed dictionary with integer key and value // pair Dictionary<int, int> obj = new Dictionarycint, int>( ); //We can only add integer value and key to the dictionary collection Obj.Add(123, 550);
Question 69.
What is the generic equivalent for ArrayList, stack, queues and hashtable?
Answer:
Below are the listed generic equivalents for each of them:
- ArrayList generic equivalent is List<int>.
- Stack generic equivalent is stack<int>.
- Queue generic equivalent is Queue<int>.
- Hashtable generic equivalent is Dictionarycint, int>.
Question 70.
What is the use of (Enumerable, (Collection, Mist, and IDictionary?
Answer:
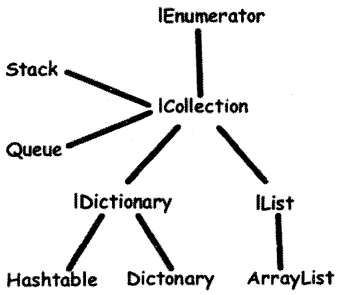
The above four entities are nothing but interfaces implemented by collections as shown in Figure 2.14:
IEnumerable: All collection classes use this interface and it helps to iterate through all the collection elements.
ICollection: This interface has the count property and it is implemented by all collection elements.
IList: This interface allows random access, insertion, and deletion into the collection. It is implemented by ArrayList.
IDictionary: This interface is implemented by hashtable and dictionary.
Question 71.
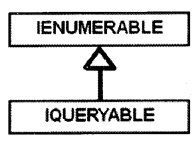
Differentiate between |Enumerable and |Queryable.
Answer:
The first important point to remember is “IQueryable” interface is inherited from “IEnumerable”, so whatever “IEnumerable” can do, “IQueryable” can also do.
There are many differences but let us discuss the one big difference. The “IQueryable” interface is useful when your collection is loaded using LINQ or Entity Framework, and you want to apply a filter on the collection.
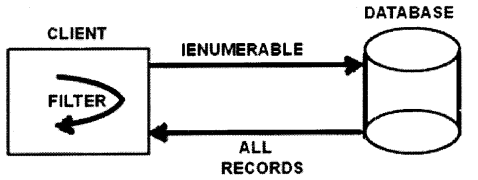
Consider the code given below which uses ‘IEnumerable” with entity framework. It is using a “Where” filter to get records whose “Empid” is “2”.
EmpEntities ent = new EmpEntities( ); IEnumerable<Employee> emp = ent.Employees; IEnumerable<Employee> temp = emp.Where(x => x.Empid == 2).ToList<Employee>( );
The filter is executed on the client side where the “iEnumerable” interface is coded. In other words, all the data is fetched from the database and then at the client, it scans and gets the record with “Empid” is “2” as shown in Figure 2.16.
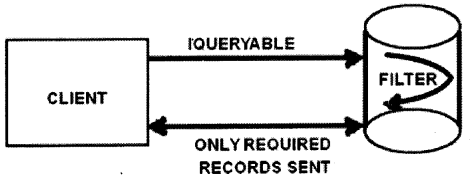
But now see the below code we have changed “IEnumerable” to “IQueryable”.
EmpEntities ent = new EmpEntities( ); IQueryable<Employee> emp = ent.Employees; IEnumerable<Employee> temp = emp.Where(x => x.Empid == 2).ToList<Employee>( );
In this case the filter is applied on the database using the “SQL” query. So the client sends a request and on the server-side a selected query is filtered on the database and only necessary data is returned as shown in Figure 2.17
So the difference between “IQueryable” and “IEnumerable” is the process of how the filter logic is executed. One executes on the client-side and the other executes on the database.
So if you working with only in-memory data collection “IEnumerable” is a good choice but if you want to query data collection which is connected with database “IQueryable” is a better choice as it reduces network traffic and uses the power of SQL (Structured Query Language).
Question 72.
What is Code Access Security (CAS)?
Answer:
CAS is the part of the .NET security model which determines whether or not a particular code is allowed to run and what kind of resources can the code access.
Question 73.
So how does CAS actually work?
Answer:
It is a four step process as shown in Figure 2.18. These steps are as follows:
- The first evidence is gathered about the assembly. In other words from where did this assembly come, who is the publisher, etc.
- Depending on evidences the assembly is assigned to a code group. In other words what rights does the assembly depending on the evidence gathered.
- Depending on the code group security rights are allocated.
- Using the security rights the assembly is run within those rights.
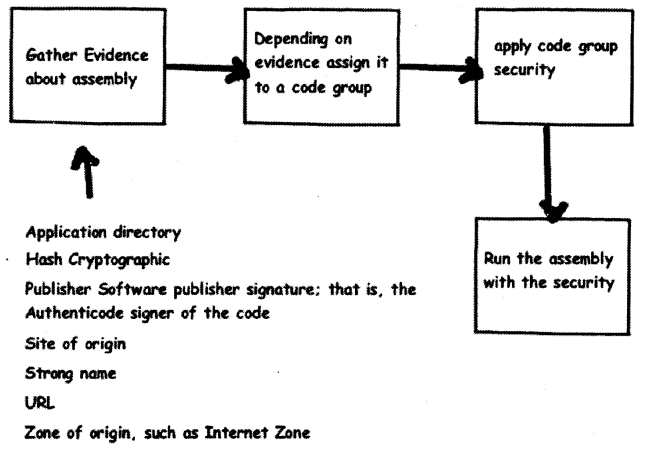
Question 74.
Is CAS supported in .NET 4.0?
Answer:
CAS is deprecated in .NET 4.0 and two major changes are brought in:
- Permission granting is no more the work of CAS; it’s now the work of the hosting model. In other words, CAS is disabled in .NET 4.0 by default. The host will decide what rights to be given to the .NET assembly.
- A new security model, i.e., security transparent model is introduced. The security transparent model puts code into separate compartments/boxes as per the risk associated. If you know a code can do something wrong you can compartmentalize the code as ‘Security transparent’ and if you have a code that you trust you can box them into ‘Security critical’.
Question 75.
What is sandboxing?
Answer:
If you have wanted to execute an untrusted third party DLL (Dynamic Link Library), you can create your own ‘app domain and assign permission sets so that your third party DLL runs under a control environment.
Question 76.
How can we create a Windows service using .NET?
Answer:
Windows Services are long-running processes that run at the background. It has the ability to start automatically when the computer boots and also can be manually paused, stopped, or even restarted.
Following are the steps to create a service:
Create a project of type “Windows Service”.
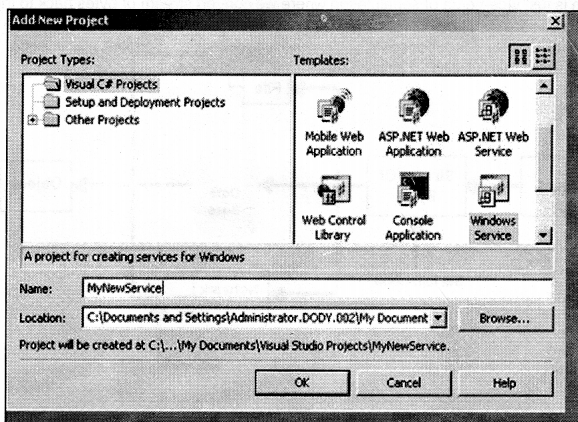
If you see, the class created it is automatically inherited from “System. ServiceProcess. ServiceBase” .
You can override the following events provided by service and write your custom code. All three main events can be used that is Start, Stop and Continue.
protected override void OnStart(string[ ] args)
{
}
protected override void OnStop( )
{
}
protected override void OnContinue( )
{
}
Now to install the service you need to do run the lnstallUtil.exe.
Install Util <Project Path>\BIN\MyNewService.exe
Question 77.
What are serialization and deserialization in .NET?
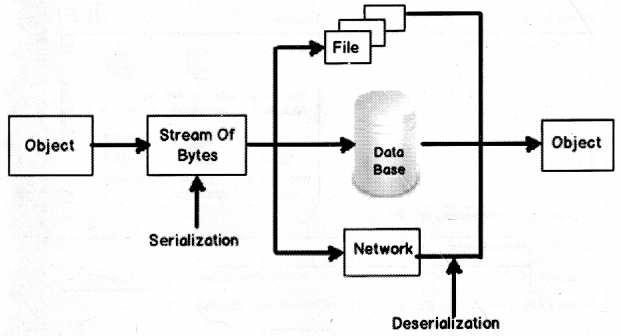
Answer:
Serialization is a process where we can convert an object state in to the stream of bytes as shown in Figure 2.20. This stream can then be persisted in a file, database, or sent over a network, etc. Deserialization is just vice-versa of serialization where we convert a stream of bytes back to the original object.
Below is a sample code of how to serialize and deserialize an object.
Let’s first start with serialization.
Step 1: Create the object and put some values
// Serialization
Customer obj = new Customer( ); // Create object
obj.CustomerCode = 123; // Set some values
Step 2: Create the file where the object is saved.
using System.Runtime.Serialization;
using System.Runtime.Serialization.Formatters.Binary;
IFormatter i = new BinaryFormatter( ); // Use the binary formatter
Stream stream = new Fi1eStrearn(“MyFi1e.txt” , FileMode.Create,
FileAccess.Write, FileShare.None); // Give file name
Step 3: Use Serialize method to save it to hard disk
i.Serialize(stream, o); // write it to the file
stream.Close( ); // Close the stream
Let’s also see a simple example of deserialization.
Step 1: Read the file
// Deserialization
IFormatter formatter = new BinaryFormatter( ); // Use binary formatter Stream stream = new FileStream(“MyFile.txt”, FileMode.Open, FileAccess.Read, FileShare.Read); // read the file
Step 2: Recreate it back to the original object.
Customer obj = (Customer)formatter.Deserialize(stream); // take data back to object
stream.Close( ); // close the stream
If you want to save as XML or any other content type use the appropriate formatter.
Question 78.
Can you mention some scenarios where we can use serialization?
Answer:
Below are some scenarios where serialization is needed:
- Passing .NET objects across network. For example, .NET remoting, Web services or WCF services use serialization internally.
- Copy and paste .NET objects on the Clipboard.
- Saving the old state of the object and reverting back when needed. For example, when the user hits the Cancel button you would like to revert back to the previous state.
Question 79.
When should we use binary serialization as compared to XML serialization?
Answer:
- Binary is smaller in size, so faster to send across the network and also faster to process.
- XML is more verbose but easy to understand and human-readable. But due to the XML structure it is complex to parse and can impact performance.
Note: Many people answer that XML serialization should be used when you have different
platforms and binary serialization should be used when you have same platforms. But this
answer is actually not right as we have lot of binary serialization methodologies like ASN
(Abstract Syntax Notation), protbuf which are cross platform and widely accepted.
So the important difference is that one is XML which readable by eyes and the binary is not.
Question 80.
What is regular expression?
Answer:
Regular expression is a pattern matching technique. Most of the data follow patterns. Some examples of common data patterns are shown in the Table
Table
By using regular expression you can represent these data patterns and utilize the same for validations and manipulation of data.
In order to use regular expression we need to create the object of “Regex” class and pass the pattern to Regex. For example, the below pattern represents data pattern of 10 character length which can be any small characters from a to z.
Regex obj = new Regex(“[a-z]{10}”);
Once you have specified the pattern as described in the previous step you can then use the “isMatch” function to check if the data matches with the pattern.
if(obj.IsMatch("shivkoirala") )
{
// proper data
}
else
{
// improper data
}
Note: In some rare cases we have seen interviewers ask to write down Regex patterns.
So we would suggest to see the video “Explain Regex.”provided on the DVD which will
help you to write down any Regex pattern easily.
Question 81.
What is timeout support in Regex (regular expression)?
Answer:
This is a new feature of .NET 4.5. Some of the regular expressions are very complex and they can take lot of time to be evaluated.
For instance below is a simple regular expression.
var regEx = new Regex(@ ”h(\d+)+$”, RegexOptions. Singleline);
If someone inputs a huge number as shown in the below code snippet. It will take more than a minute to resolve the expression leading to a lot of loads on the application. So we would like to give a time out on the expression. So if the validation takes more than a specific interval we would like the application to give up and move ahead.
var match - regEx. Match(“123453109839109283090492309480329489812093809x’);
In .NET 4.5 we can now provide the timeout value as parameter on the constructor. For instance in the below code we have provided 2 seconds timeout on the Regex (regular expression). So if it exceeds more than 2 second “RegexMatchTimeOutException” will occur.
try
{
var regEx = new Regex(A(\d+)+$", RegexOptions.Singleline,
TimeSpan.FromSeconds(2));
var match = regEx.Match
("123453109839109283090492309480329489812093809x");
}
catch (RegexMatchTimeOutException ex)
{
Console.WriteLine("Regex Timeout");
}
Question 82.
Can you explain the concept of “Short Circuiting”?
Answer:
Short circuiting occurs when you do logical operations like ‘AND’ and ‘OR’.
“When we use short circuit operators only necessary evaluation is done rather than full evaluation.”
Let us try to understand the above sentence with a proper example. Consider a simple “AND” condition code as shown below. Please note we have only one operator in the below code.
if (Condition1 & Condition2)
{
}
In the above case “Condition2″ will be evaluated even if “Condition1” is “false”. Now if you think logically, it does not make sense to evaluate “Condition 2”, if “Condition 1” is false. It is a AND condition right? So if the first condition is false it means the complete AND condition is false and it makes no sense to evaluate “Condition2”.
There’s where we can use short circuit operator “&&”. For the below code “Condition 2” will be evaluated only when “Condition 1” is true.
if(Condition1 && Condition2)
{
}
The same applies for “OR” operation. For the below code (please note its only single pipe (” j “).) “Condition2” will be evaluated even if “Conditionl” is “true”. If you think logically we do not need to evaluate “Condition2” if “Conditionl” is “true”.
if(Condition1 | Condition2)
{
}
So if we change the same to double pipe (” | | “), i.e., implement short circuit operators as shown in the below code, “Condition2” will be evaluated only if “Conditionl” is “false”.
if(Condition1 || Condition2)
{
}
Question 83.
What is the difference between “Typeof” and “GetType”?
Answer:
Both “Typeof” and “GetType” help you to get the type. The difference is from where the information is extracted. “Typeof” gets the type from a class while “GetType” gets type from an object.
Question 84.
Will the following C# code compile?
Answer:
double db1 = 109.22;
int i = dbl;
No, the above code will give an error. Double size is larger than “int” so an implicit conversion will not take place. For that we need to do explicit conversion. In the below code we have done an explicit conversion.
double dbl = 109.22;
int i =(int) dbl; // this is explicit conversion / casting
Also note after explicit conversion we will have data loss. In variable ” i” we will get “109” value, the decimal values will be eliminated.
Question 85.
Explain the use of IComparable in C#.
Answer:
“|Comparable” interface helps to implement custom sorting for collections in C#. Let us try to understand the same concept with a simple C# example. For instance let’s say you have a list collection of people names as shown in the below code.
List<string> Peoples = new List<string>( );
Peoples.Add("Shiv");
Peoples.Add("Raju");
Peoples.Add("Sukesh");
Peoples.Add("Ajay");
foreach (string str in Peoples)
{
Console.WriteLine(str) ;
}
Now if you run the above program you will see that we have not applied sorting on the collection. It displays data as they were inserted.
Shiv
Raju
Sukesh
Ajay
But now if you call “Peoples. Sort ()” method on the collection you will get the following sorted output on the “name” value in ascending order.
Ajay
Raju
Shiv
Sukesh
But now let’s say that we need the person’s age also to be added in the list with the person name value. So logically you will create a, “Person” class with “Name” and “Age” properties as shown in the code below.
class Person
{
private string _Name;
public string Name
{
get { return _Name; }
set { _Name = value; }
}
private int _Age;
public int Age
{
get { return _Age; }
set { _Age = value; }
}
}
Once you create the class you would create an object of the Person class and add it to the list collection as shovyn in the below code snippet.
class Program
{
static void Main(string[ ] args)
{
List<Person> Peoples = new List<Person>( );
Peoples.Add(Createperson("Shiv", 20));
Peoples.Add(Createperson("Raju", 20));
Peoples.Add(Createperson("Sukesh", 30));
Peoples.Add(Createperson("Ajay", 40)) ;
Peoples.Sort( );
foreach (Person obj in Peoples)
{
Console.WriteLine(obj.Name + " " + obj.Age);
}
}
static Person Createperson(string Name, int Age)
{
Person obj = new Person( );
obj.Name = Name;
obj.Age = Age;
return”'obj ;
}
}
But if you try to call the “Sort” method in the given List, there would be confusion like sort() method works on values given for “Name” or “Age”.
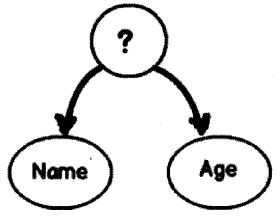
If you run the application it will throw up the below exception text. The exception .text needs specific direction on how the sorting should work. This direction can be provided by using “incomparable” interface as shown in Figure 2.21.
Unhandled Exception: System. InvalidOperationException: Failed to compare two elements in the array. —> System. ArgumentException: At least one object must implement |Comparable.
So in order to show a proper direction for the sort logic we need to implement ” incomparable” interface as shown in the code below. The logic of “Sort” method needs to be defined in the “CompareTo” method.
class Person: IComparable<Person>
{
private string _Name;
public string Name
{
get { return _Name; }
set { _Name = value; }
}
private int _Age;
public int Age
{
get { return _Age; }
set { _Age = value; }
}
public int CompareTo(Person other)
{
if (other,Age == this.Age)
{
return this.Name.CompareTo(other.Name);
}
else
{
return other.Age.CompareTo(this.Age);
}
}
}
You can see in the “CompareTo” method that we have applied the logic saying if the “Age” value is same then sort by using the “Name” value else use “Age” value. If you run the application you would get the following output. You can see for “40” and “30” have been sorted on the basis of “Age” but for the remaining people the age is same so “Name” values have been sorted.
Loki 40
Sukesh 30
Ajay 20
Madan 20
Raju 20
Shiv 20
So “icomparable” interface customized sorting logic on the given list.
Question 86.
What is difference between Icomparable and IComparer?
Answer:
Pre-requisite: Please read “Explain the use of Icomparable in C#. ”, before reading this answer.
“Icomparable” interface helps you to implement a default sort implementation for the collection. But what if we want to sort using multiple criteria. For those instances “icomparable” has a limitation.
For example, if we want to sort the list by “Name” under some situation or sort by “Age” under some other situation we need to implement “IComparer” interface.
So the first step is to create different classes for each sort criteria. These classes will implement “IComparer” interface and will have sorting logic defined in the “Compare” method. You can see we have two different classes defined “CompareByName” and “CompareByAge”. One compares on the basis of “Name” and the other on the basis of “Name”.
class CompareByName: IComparer<Person>
{
public int Compare(Person x( Person y)
{
return string.Compare(x.Name, y.Name);
}
}
class CompareByAge: IComparer<Person>
{
public int Compare(Person x, Person y)
{
if (x.Age > y.Age) return 1;
if (x.Age < y.Age) return -1;
return 0;
}
}
If you see the logic for “CompareByName” it is simple. It uses the string comparison to evaluate the “Name” value sorting. But when we talk about numeric comparison there are three possible outputs Greater than, Less than or Equal. So if you see “CompareByAge” class it returns three values 1 (Greater than), -1 (Less than) and 0 (for Equal to).
Now that we have created the separate logics we can now invoke the ” Peoples” list by passing the class object. So for example if we want to sort by name, you will use the below code snippet.
Peoples.Sort(new CompareByName( ));
The output of the above code is nothing but alphabetically sorted data.
Ajay 20
Loki 40
Madan 20
Raju 20
Shiv 20
Sukesh 30
If you invoke the Sort ( ) method of the list by using the Age logic it will throw an output sorted on Age value.
Peoples. Sort (new CompareByAge( ));
Ajay 20
Raju 20
Shiv 20
Madan 20
Sukesh 30
Loki 40
So the difference is really default internal implementation or customizable external implementation. When we use “incomparable” we can have only one default sorting logic and that logic goes inside the collection itself. For “icomparator” the logic is outside the collection, in other words more extensible and the collection is not disturbed as shown in Figure 2.22.
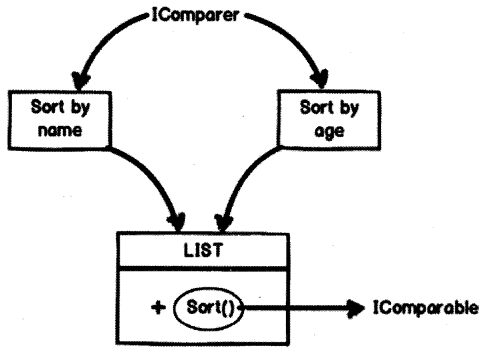
Question 87.
Can you explain Lazy Loading?
Answer:
Lazy loading is a concept where we delay the loading of the object unit the point where we need it. Putting in simple words on demand object loading rather than loading the objects unnecessarily.
For example, consider the below example where we have a simple “Customer” class and this “Customer” class has many “Order” objects inside it. Have a close look at the constructor of the “Customer” class. When the “Customer” object is created it also loads the “Order” object at that moment. So even if we need or do not need the address object, it is still loaded.
But how about just loading the “Customer” object initially and then on demand basis load the “Order” object,
public class Customer
{
private List<Order> _Orders= null;
...
...
public Customer( )
{
_CustomerName = "Shiv";
_Orders = LoadOrders() ; // Loads the address object even though
//not needed
}
private List<Order> LoadOrders( )
{
List<Order> temp = new List<Order>( );
Order o = new Order( );
o.OrderNumber = "ord1001";
temp.Add(o);
o = new Order();
o.OrderNumber = "ord1002";
temp.Add(o);
return temp;
}
}
So let’s consider you have client code which consumes the “Customer” class as shown below. So when the “Customer” object is created no “Order” objects should be loaded at that moment. But as soon as the “foreach” loop runs you would like to load the “Order” object at that point (on demand object loading).
Customer o = new Customer(); // Address object not loaded Console.WriteLine(o.CustomerName);
foreach (Order ol in o.Orders) // Load address object only at this moment
{
Console.WriteLine(ol.OrderNumber);
}
Question 88.
So how do we implement “Lazy Loading”?
Answer:
So for the above example if we want to implement lazy loading we will need to make the following changes:
- Remove the “Order” object loading from the constructor.
- In the “Order” get property, load the “Order” object only if it is not loaded.
public class Customer
{
private List<Order> _Orders= null;
...
...
public Customer( )
{
_CustomerName = "Shiv";
}
public List<Order> Orders
{
get
{
if (_Orders == null)
{
_Orders = LoadOrders( );
}
return _Orders;
}
}
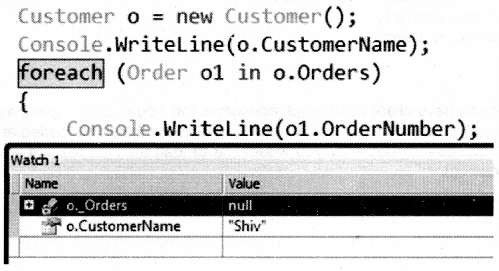
}
Now if you run the client code and halt your debugger just before the “for each” loop runs over the “Order” object, you can see the “Order” object is null (i.e., not loaded) as shown in Figure 2.23. But as soon as the “ForEach” loop runs over the “Order” object, it creates the “Order” object collection.
Question 89.
Are there any readymade objects in .NET by which we can implement lazy loading?
Answer:
In .NET we have “Lazy<T>” class which provides automatic support for lazy loading. So let’s say if you want to implement “Lazyo” in the above code we need to implement two steps for the same:
Create the object of orders using the “Lazy” generic class.
private Lazy<List<Order>> _Orders= null;
Attach this Lazyo object with the method which will help us load the order’s data.
Orders = new Lazy<List<Order>>(() => LoadOrders( ));
Now as soon as any client makes a call to the “_Orders” object, it will call the “LoadOrders” method to load the data.
You will get the “List<Orders>” data in the “Value” property.
public List<Order> Orders
{
get
{
return _Orders.Value;
}
}
Below goes the full code for the same
public class Customer
{
private Lazy<List<Order>> _Orders= null;
public List<Order> Orders
{
get
{
return _Orders.Value;
}
}
public Customer( )
{
// Makes a database trip
_CustomerName = "Shiv";
_Orders = new Lazy<List<Order>>(( ) => LoadOrders( ));
}
}
Question 90.
What are the advantages/disadvantages of lazy loading?
Answer:
Below are the advantages of lazy loading:
- Minimizes start-up time of the application.
- The application consumes less memory because of on-demand loading.
- Unnecessary database SQL execution is avoided.
The disadvantage is that the code becomes complicated. As we need to do checks if the loading is needed or not. So must be there is a slight decrease in performance.
But the advantages are far more than the disadvantages.
FYI: The opposite of Lazy loading is Eager loading. So in eager loading we load the
all the objects in memory as soon as the object is created.
Question 91.
What is the difference between “is” and “as” keyword?
Answer:
“is” keyword is useful to check if objects are compatible with a type. For instance in the below code we are checking if “ocust” object is a type of “Customer” class.
object ocust = new Customer( );
if (ocust is Customer)
{
“as” keyword helps to do conversion from one type to other type. For instance in the below code we are converting object to a string data type. If the “as” keyword is not able to typecast it returns NULL
object o = “interview”; string str = o as string;
Question 92.
What is the use of the “Yield” keyword?
Answer:
“Yield helps you to provide custom stateful iteration over .NET collections.”
There are two scenarios where “yield” keyword is useful:
- Customized iteration through a collection without creating a temporary collection.
- Stateful iteration.
Scenario 1: Customized iteration through a collection
Let’s try to understand what customized iteration means with an example. Consider the below code.
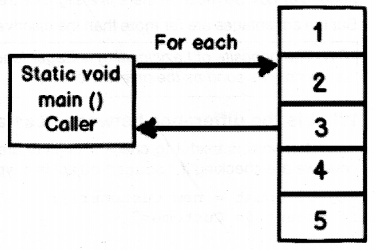
Let say we have a simple list called as “MyList” which has collection of five consecutive numeric values 1,2, 3, 4 and 5 as shown in Figure 2.24. This list is browsed/iterated from console application from within static void Main () method.
For now let’s visualize the “Main ( ) ” method as a caller. So the caller, i.e., “Main ( ) ” method calls the list and displays the items inside it. Simple…till now ;-).
static List<int> MyList = new List<int>( );
static void FillValues( )
{
MyList.Add(1);
MyList.Add(2);
MyList.Add(3);
MyList.Add(4);
MyList.Add(5);
}
static void Main(string[ ] args) // Caller
{
FillValues( ); // Fills the list with 5 values
foreach (int i in MyList) // Browses through the list
{
Console.WriteLine(i);
}
Console.ReadLine( );
}
Now let me complicate this situation lets say the caller only wants values greater than “3” from the collection. So the obvious thing as a C# developer we will create a function as shown below. This function ‘will be temporary collection of given values.
In this temporary collection we will first add values which are greater than “3” and return the same to the caller. The caller can then iterate through this collection.
static IEnumerable<int> FilterWithoutYield( )
{
List<int> temp = new List<int>( );
foreach (int i in MyList)
{
if (i > 3)
{
temp.Add(i);
}
}
return temp;
}
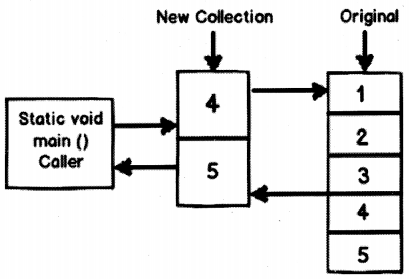
Now the above approach is fine but it would be great if we would get rid of the collection, so that our code becomes simple as shown in Figure 2.25. This where “yield” keyword comes to help. Below is a sample code how we have used yield.
“yield” keyword will return back the control to the caller, the caller will do its work and re-enter the function from where it had left and continue iteration from that point onwards. In other words “yield” keyword moves control of the program to and from between caller and the collection.
static IEnumerable<int> FilterWithYield()
{
foreach (int i in MyList)
{
if (i > 3) yield return i;
}
}
So for the above code, following are steps how the control will flow between caller and collection. You can also see the pictorial representation in the Figure 2.26.
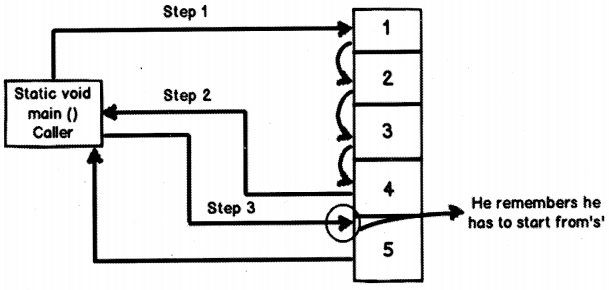
• Step 1: Caller calls the function to iterate for number’s greater than 3.
• Step 2: Inside the function the for loop runs from 1 to 2, from 2 to 3 until it encounters value greater than “3” i.e. “4”. As soon as the condition of value greater than 3 is met the “yield” keyword sends this data back to the caller.
• Step 3: Caller displays the value on the console and re-enters the function for more data. This time when it reenters, it does not start from first. It remembers the state and starts from “5”. The iteration continues further as usual.
Scenario 2: Stateful iteration
Now let us add more complications to the above scenario. Let’s say we want to display running total of the above collection. What do I mean?.
In other words we will browse from 1 to 5 and as we browse we would keep adding the total in variable.
So we start with “1” the running total is “1 ”, we move to value “2” the running total is previous value “1 ” plus current value “2”, i.e., “3” and so on.
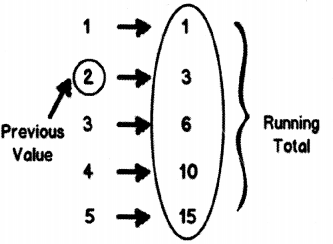
Figure 2.27 shows the pictorial representation of the running total looks like.
In other words we would like to iterate through the collection and as we iterate would like to maintain running total state and return the value to the caller (i.e., console application). So the function now becomes something as shown below. The “runningtotal” variable will have the old value every time the caller re-enters the function.
static IEnumerable<int> RunningTotal( )
{
int runningtotal=0;
int index=0;
foreach(int i in MyList)
{
index = index + 1;
if(index==l)
{
runningtotal = i;
}
else
{
runningtotal = i + runningtotal;
}
yield return (runningtotal);
}
}
Following is the caller code.
foreach (int i in RunningTotal( ))
{
Console.WriteLine(i);
}
Console.ReadLine( );
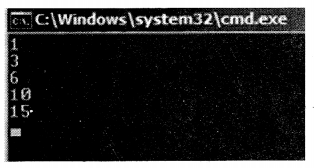
The output of the above program is shown in Figure 2.28.
Question 93.
What is the difference between “==” and .Equals()?
Answer:
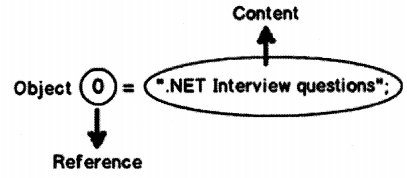
When we create any object there are two parts to the object one is the content and the other is reference to that content as shown in Figure 2.29.
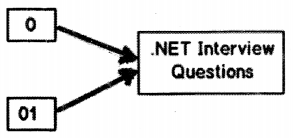
So for example if you create an object as shown in below code:
1. “.NET Interview questions” is the content.
2. “o” is the reference to that content.
object o = “.NET Interview questions”;
“==” compares if the object references are same while ” . Equals ( )” compares if the contents are same as shown in Figure 2.31.
So if you run the below code both “==” and “.Equals ( ) ” return true because content as well as references are same as shown in Figure 2.30.
object o = “.NET Interview questions”;
object o1 = o;
Console.WriteLine(o == o1) ;
Console.WriteLine(o.Equals(o1));
Console.ReadLine();
True True
Now consider the below code where we have the same content but they point towards different instances. So if you run the below code “==” will return false and “.EqualsO” will return true.
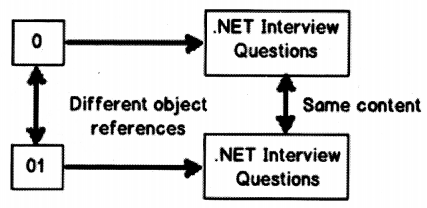
object o = “.NET Interview questions”;
object ol = new string(“.NET Interview questions”.ToCharArray( ));
Console.WriteLine(o == o1);
Console.WriteLine(o.Equals(o1)) ;
Console.ReadLine();
False True
When you are using string data type it always does the content comparison. In other words, you either use “. Equals ()” or “==” it always does the content comparison.
Question 94.
What’s the difference between catch with parameter and catch without parameter?
Answer:
First, let’s try to understand this question:
catch(Exception e)
{
...
}
VS
Catch
{
...
}
For this interview question, many people answer, “The second one will cause compile error”. But both the codes will work properly. Actually, from .NET 2.0, there is no difference. But in the initial versions of .NET, i.e., prior 2.0 some of the exceptions thrown by some COM components did not translate to “Exception” compatible objects.
From .NET 2.0 both codes will execute properly and there is no difference between them internally. Both catches will handle all kinds of exceptions.
After 2.0 a catch which does have any code written in it gives a warning as shown in Figure 2.23. So many developers mark this as a difference.
IMAGE
But you can always overcome this issue by not putting a variable as shown in the code below.
catch (Exception)
{
}
Question 95.
What are attributes and why do we need it?
Answer:
“Attribute is nothing but a piece of information”.
This information can be attached to your method, class, namespace, assembly, etc. Attributes are part of your code this makes developers’ life easier as it can see the information right up front in the code while it is calling the method or accessing the class and take actions accordingly.
For instance below is a simple class where “Method” is decorated by the “Obsolete” attribute. Attributes are defined by using the ” []” symbol. So when developers starting coding in this class they are alerted that “Method” is obsolete and code should be now written in “NewMethodl”.
public class Class1
{
[Obsolete]
public void Method1 ( )
{
}
public void NewMethod1( )
{
}
}
In the same way, if somebody is trying to create an object of “Class1” it gets an alert in the tooltip as shown in the below code snippet that “Method1” is obsolete and it should use “NewMethodl” as shown in Figure 2.33.
So in short Attributes are nothing small piece of information which is embedded declaratively in the code itself which developers can see upfront.

In case you want to show some message to the developers you can pass the message in the “Obsolete” attribute as shown in the below code snippet.
[Obsolete("Please use NewMethodl")]
public void Methodl( )
{
}
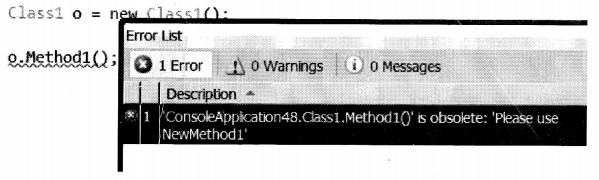
If you want to be a bit strict and do not developers to use that method, you can pass “true” to the “Obsolete” attribute as shown in the below code.
[Obsolete("Please use NewMethodl", true)]
public void Methodl()
{
}
If you want to be a bit strict and do not developers to use that method, you can pass “true” to the “Obsolete” attribute as shown in the below code.
[Obsolete("Please use NewMethodl", true)]
public void Methodl()
{
}
Now in case, developers try to make a call to “Method1” they will get errors and not just a simple warning.
Question 96.
How can we create custom Attributes?
Answer:
The “Obsolete” attribute which we discussed at the top is a readymade attribute. To create custom attributes you need to inherit from the Attribute class. Below is a simple “HelpAttribute” which has a “HelpText” property.
class HelpAttribute: Attribute
{
public string HelpText { get; set; }
}
"HelpAttribute" is applied to the "Customer" as shown in the code below. Now developers who see this class, see the information right in the front of their eyes.
[Help(HelpText="This is a class")]
class Customer
{
private string _CustomerCode;
[Help(HelpText = "This is a property")]
public string CustomerCode
{
get { return _CustomerCode; }
set { _CustomerCode = value; }
}
[Help(HelpText = "This is a method")]
public void Add( )
{
}
}
Question 97.
How can we mark a method as deprecated?
Answer:
Refer to the previous answer.
Question 98.
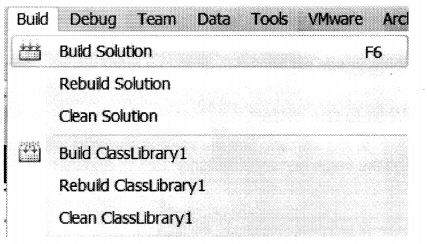
What is the difference between Build Solution, Rebuild Solution, and Clean Solution menus?
Answer:
Build solution menu: This will perform an incremental build. In other words, it will only build code files that have changed. If they have not changed those files will not touch.
Rebuild solution menu: This will delete all current compiled files (i.e., exe and dll’s) and i will build everything from scratch, irrespective if there is a code change in the file or not.
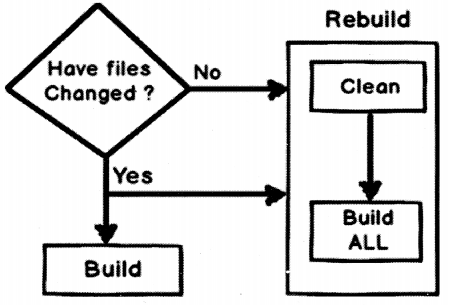
Clean solution menu: This menu will delete all compiled files (i.e., EXE’s and DLL’s) from “bin” / “obj” directory.
Now if you read the above three points I have discussed you can conclude that:
Rebuild = Clean + Build
So the next question would be If you do a “Rebuild” and if you do “Clean” + “Build”, what is the difference?
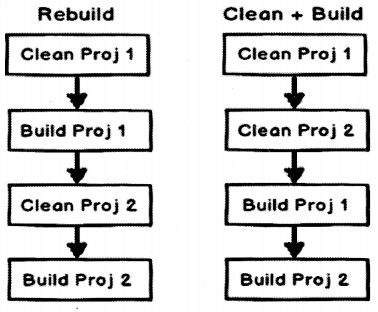
The difference is the way they build and clean sequence happens for every project. Let’s say if your solution has two projects “Projl” and “Proj2”.
If you do a rebuild it will take “Projl”, clean (delete) the compiled files for “Projl” and build it. After that it will take the second project “Proj2”, clean compiled files for “Proj2” and compile “Proj2”.
But if you do a “Clean” and “Build”. It will first delete all compiled files for “Proj1” and “Proj2” and then it will build “Projl” first followed by “Proj2”.
The below image explains the same in a more visual format.
Question 99.
What is the difference between i++ and ++i?
Answer:
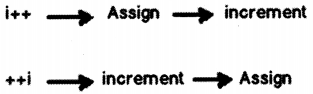
i++: In this scenario first the value is assigned and then increment happens. In the below code snippet first the value of “i” is assigned to ” j ” and then “i” is incremented.

++i: In this scenario first the increment is done and then the value is assigned. In the below code snippet value of ” j ” is 2 and the value of “i” is also “2”.
If you visualize it in a pictorial manner below is how it looks like. So i++ is a postfix, it first assigns and then increments. While + + i is a prefix, it first increments and then assigns the value.
Below is some sample codes where postfix and prefix fit in.
while (i < 5) //evaluates conditional statement
{
//some logic
++i; //increments i
}
while (i++ < 5) //evaluates conditional statement with i value before increment
{
//some logic
}
int i = 0;
int [ ] MyArray = new int[2];
MyArray[i++] = 1234; //sets array at index 0 to '1234' and i is incremented
MyArray[i] = 5678; //sets array at index 1 to '5678'
int temp = MyArray[—i]; //temp is 1234
Question 100.
When should we use “??” (NULL Coalescing operator)?
Answer:
“??” is a null coalescing operator. If you see the English meaning of coalescing it says “consolidate together”. Coalescing operator returns the first non-null value from a chain. For example, below is a simple coalescing code that chains four strings.
So if “str1” is null it will try “str2”, if “str2″ is null it will try “str3” and so on until it finds a string with a non-null value.
string final =str1?? str2?? str3?? str4;
Question 101.
Explain the need for NULLABLE types.
Answer:
It is difficult to assign null directly for value types like int, bool, double, etc. By using nullable types you can set value types as null. To create a nullable type we need to put ” ?” before the data type as shown in the below code.
int? num1 = null;
Question 102.
In what scenario’s we will use NULLABLE types?
Answer:
The biggest user of nullable types is when you are reading values from the database. The database is one place where there is high possibility of columns having nulls. So when we want to read those values into value types nullable types make it easy as shown in the below code.
while (oreader.Read( ))
{
int? salary = oreader["Salary"] as int? ;
}
Question 103.
What is the benefit of coalescing?
Answer:
You do not need to write long if condition as shown below.
if (str1 != null)
{
final = str1;
}
else
{
if (str2 != null)
{
final = str2;
}
else
{
if (str3 != null)
{
final = str3;
}
else
{
if (str4 != null)
{
final = str4;
}
}
}
}