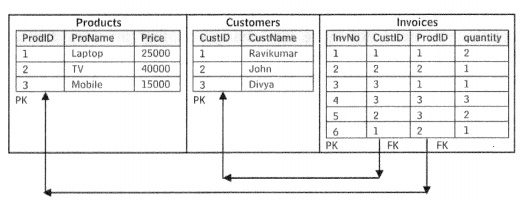
Python Data Persistence – RDBMS Products
Relational Software Inc. (now Oracle Corp) developed its first SQL-based RDBMS software called Oracle V2. IBM introduced System-R as its RDBMS product in 1974 and followed it by a very successful DB2 product.
Microsoft released SQL Server for Windows NT in 1994. Newer versions of MS SQL server are integrated with Microsoft’s .NET Framework.
SAP is an enterprise-level RDBMS product targeted towards UNIX-based systems being marketed as Enterprise Resource Planning (ERP) products.
An open-source RDBMS product named MySQL, developed by a Swedish company MySQL AB was later acquired by Sun Microsystems, which in turn has, now, been acquired by Oracle Corporation. Being an open-source product, MySQL is a highly popular choice, after Oracle.
MS Access, shipped with the Microsoft Office suite, is widely used in small-scale projects. The entire database is stored in a single file and, hence, is easily portable. It provides excellent GUI tools to design tables, queries, forms, and reports.
PostgreSQL is also an open-source object-oriented RDBMS, which has evolved from the Ingres project of the University of California, Berkley. It is available for use on diverse operating system platforms and SQL implementation is supposed to be closest to SQL standard.
SQLite is a very popular relational database used in a wide variety of applications. Unlike other databases like Oracle, MySQL, etc., SQLite is a transactional SQL database engine that is self-contained and serverless. As its official documentation describes, it is a self-contained, serverless, zero-configuration, transactional SQL database engine. The entire database is a single file that can be placed anywhere in the file system.
SQLite was developed by D. Richard Hipp in 2000. Its current version is 3.27.2. It is fully ACID compliant which ensures that transactions are atomic, consistent, isolated, and durable.
Because of its open-source nature, very small footprint, and zero-configuration, SQLite databases are popularly used in embedded devices, IoT, and mobile apps. Many web browsers and operating systems also use SQLite database for internal use. It is also used as prototyping and demo of larger enterprise RDBMS.
Despite being very lightweight, it is a full-featured SQL implementation with all the advanced capabilities. SQLite database can be interfaced with most of the mainstream languages like C/C++, Java, PHP, etc. Python’s standard library contains the sqlite3 module. It provides all the functionality for interfacing the Python program with the SQLite database.
7.4 SQLite installation
Installation of SQLite is simple and straightforward. It doesn’t need any elaborate installation. The entire application is a self-contained executable ‘sqlite3.exe’. Official website of SQLite, (https://sqIite.org/download.html) provides pre-compiled binaries for various operating system platforms containing the command line shell bundled with other utilities. All you have to do is download a zip’archive of SQLite command-line tools, unzip to a suitable location and invoke sqlite3.exe from DOS prompt by putting name of the database you want to open.
If already existing, the SqLite3 database engine will connect to it; otherwise, a new database will be created. If the name is omitted, an in memory transient database will open. Let us ask SQLite to open a new
mydatabase.sqlite3.
E:\SQLite>sqlite3 mydatabase.sqlite3
SQLite version 3.25.1 2018-09-18 20:20:44
Enter “.help” for usage hints.
sqlite>
In the command window a sqlite prompt appears before which any SQL query can be executed. In addition, there “dot commands” (beginning with a dot “.”) typically used to change the output format of queries, or to execute certain prepackaged query statements.
An existing database can also be opened using .open command.
E:\SQLite>sqlite3
SQLite version 3.25.1 2018-09-18 20:20:44
Enter “.help” for usage hints.
Connected to a transient in-memory database.
Use “.open FILENAME” to reopen on a persistent database.
sqlite> .open test.db
The first step is to create a table in the database. As mentioned above, we need to define its structure specifying name of the column and its data type.
SQUte Data Types
ANSI SQL defines generic data types, which are implemented by various RDBMS products with a few variations on their own. Most of the SQL database engines (Oracle, MySQL, SQL Server, etc.) use static typing. SQLite, on the other hand, uses a more general dynamic type system. Each value stored inSQLite database (or manipulated by the database engine) has one of the following storage classes:
• NULL
• INTEGER
• REAL ‘
• TEXT
• BLOB
A storage class is more general than a datatype. These storage classes are mapped to standard SQL data types. For example, INTEGER in SQLite has a type affinity with all integer types such as int, smallint, bigint, tinyint, etc. Similarly REAL in SQLite has a type affinity with float and double data type. Standard SQL data types such as varchar, char,nchar, etc. are equivalent to TEXT in SQLite.
SQL as a language consists of many declarative statements that perform various operations on databases and tables. These statements are popularly called queries. CREATE TABLE query defines table structure using the above data types.
CREATE TABLE
This statement is used to create a new table, specifying following details:
• Name of new table
• Names of columns (fields) in the desired table
• Type, width, and the default value of each column.
• Optional constraints on columns (PRIMARY KEY, NOT NULL, FOREIGN KEY)
Example
CREATE TABLE table_name (
column 1 datatype [width] [default] [constraint],
column2 ,
column3 …,
) ;